
%20(1200%20x%20485%20px).png)


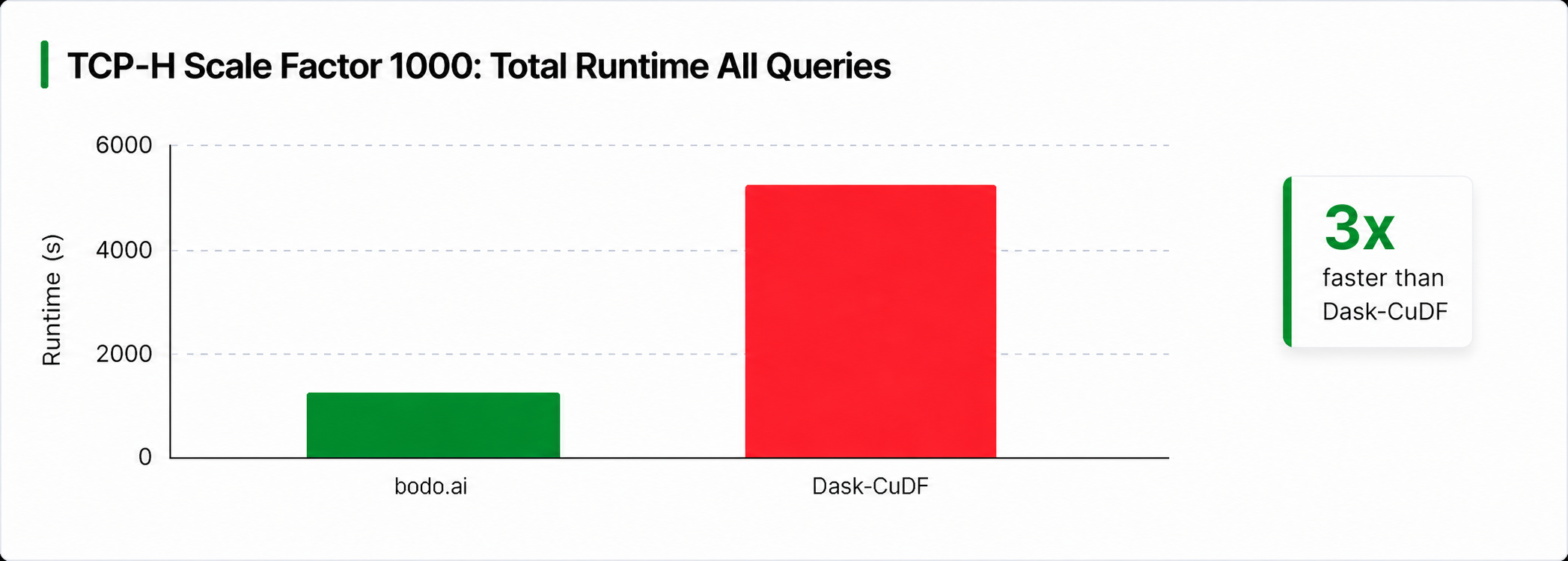
In our previous blog post, we introduced GPU acceleration in Bodo DataFrames and demonstrated the performance advantage of Bodo’s Single Program Multiple Data (SPMD) execution model over task-based architectures such as Dask-CuDF, showing more than a 4× speedup on a Python implementation of a TPC-H query. In this post, we extend that comparison to all 22 TPC-H queries on a multi-node GPU cluster and show an overall speedup of more than 3× over Dask-CuDF across the full benchmark suite.
TPC-H is a decision support benchmark designed to evaluate a system’s ability to execute complex analytical queries efficiently at scale. Rather than using SQL directly, we use Python implementations of the queries written with the Pandas API. As a result, these measurements are not comparable to officially published TPC-H results. However, Python-based implementations of TPC-H are widely used in the DataFrame ecosystem because they stress common analytical operations such as joins, aggregations, filtering, and column expressions.
The full TPC-H suite highlights the impact of the choice of parallel execution model on distributed DataFrame performance. Bodo’s MPI-based Single Program Multiple Data (SPMD) execution model avoids many of the coordination and scheduling overheads inherent to task-based systems by executing a single distributed program collectively across all workers. This enables efficient worker-to-worker communication and allows Bodo to take advantage of GPUDirect technologies for accelerated GPU communication while avoiding unnecessary host-device transfers. These differences become particularly important for the large distributed joins and aggregations that dominate many TPC-H queries, allowing Bodo to achieve more than a 3× speedup over Dask-CuDF despite both systems relying on the same underlying libcudf kernels for DataFrame operations.
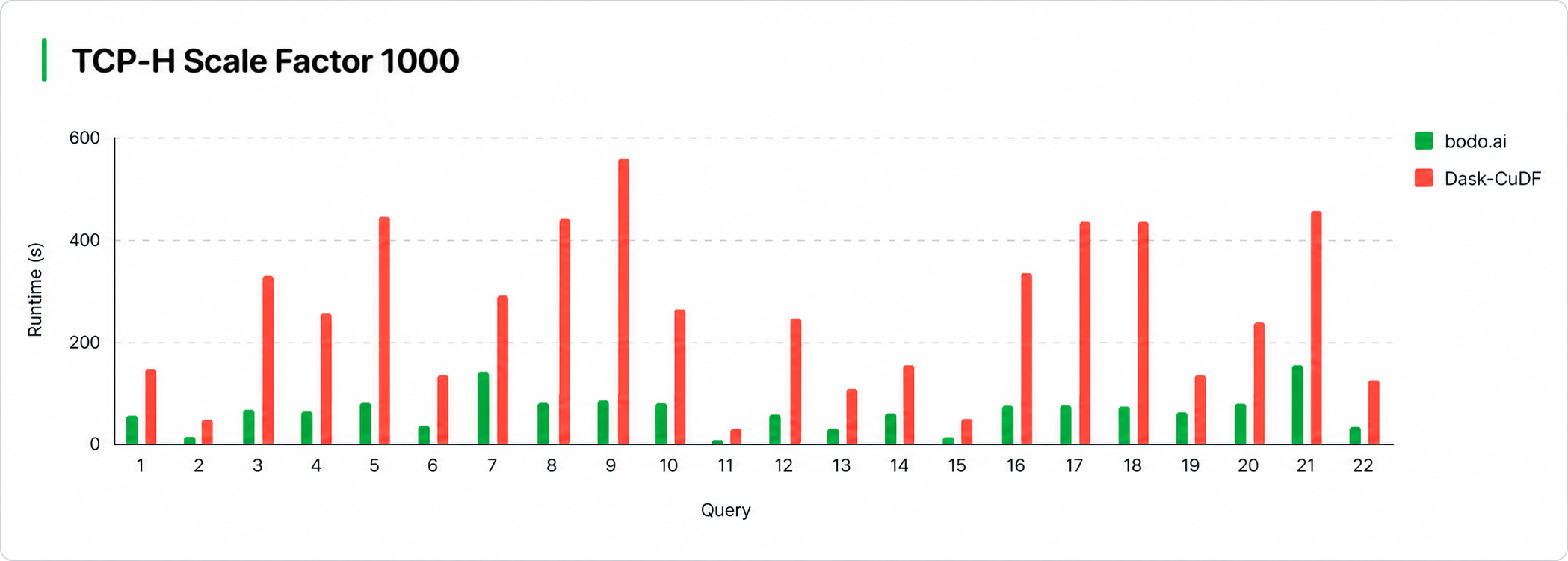
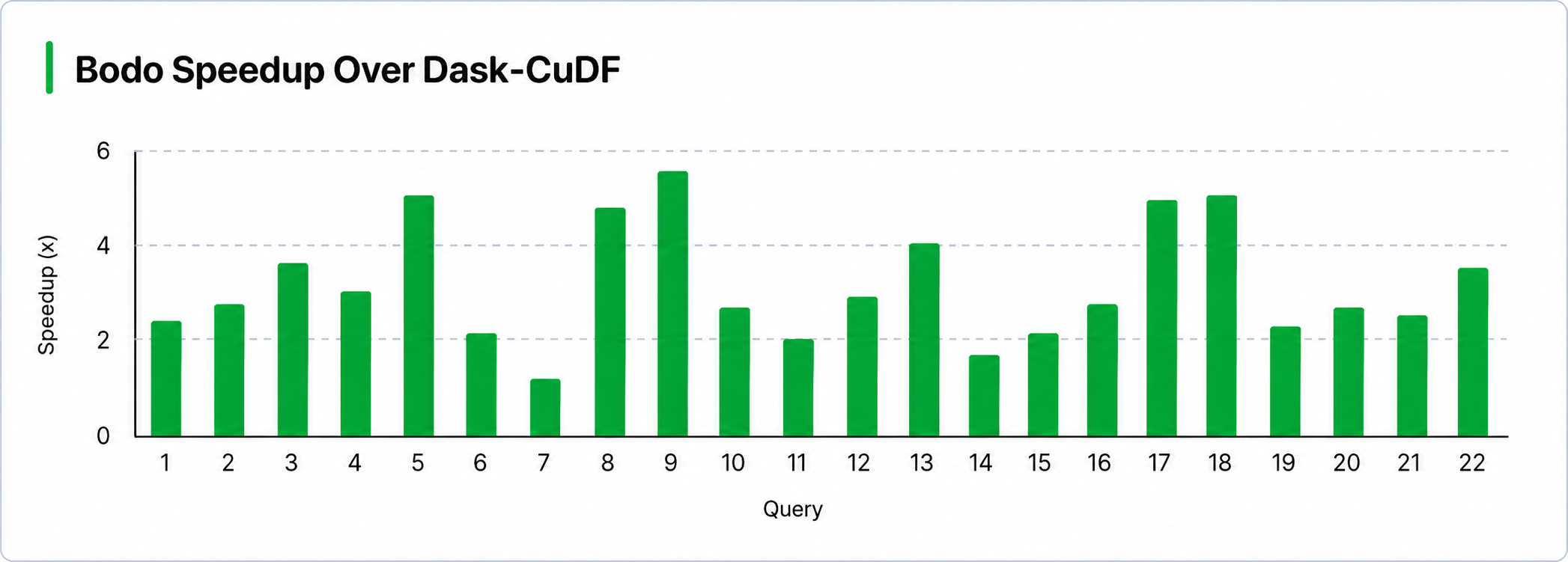
Overall, Bodo demonstrates a roughly 3× improvement over the Dask-CuDF baseline, with individual query speedups ranging from 1.6× to 5.8×. The largest gains were observed for Q9 (5.8×), Q5 (4.9×), and Q18 (4.9×), while the smallest gains were seen for Q7 (1.6×), Q14 (1.9×), and Q11 (2.0×). In general, queries with larger joins and aggregations saw the highest speedups. Both joins and aggregations require workers to exchange data in an all-to-all pattern so that rows with matching keys are colocated in the same partition, making shuffle performance a critical factor.
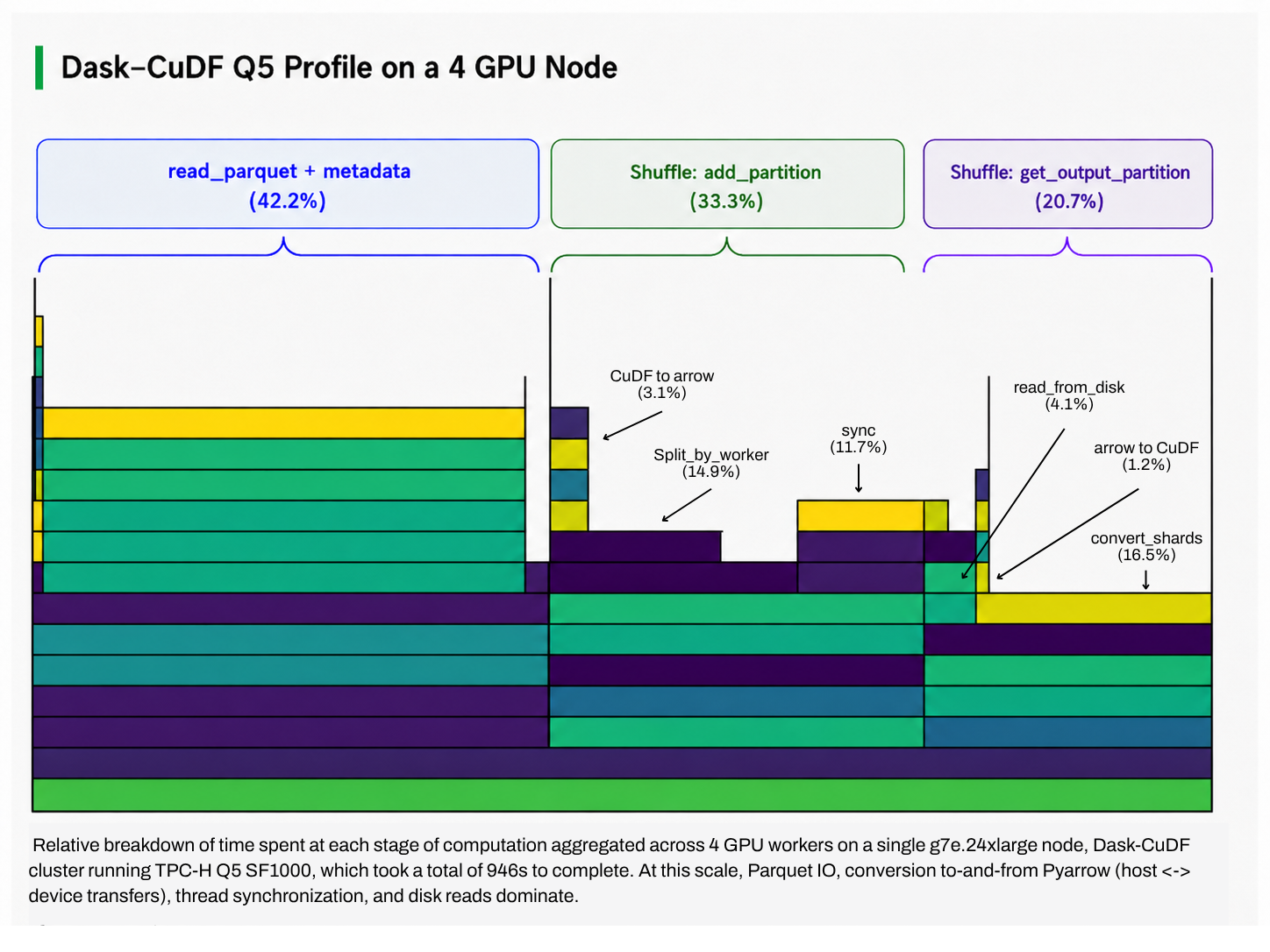
Dask’s shuffle is a bottleneck due to their task based architecture, which prevents workers from communicating with each other directly without expensive workarounds. In Dask’s P2P shuffle, each worker transfers their data to host, and sends chunks of data over the network to all other workers. Workers then receive new chunks over the network and write them to disk, before reading chunks from disk and transferring them back to device to resume the computation. Transferring data between host<-> device in addition to disk IO adds significant overhead.
Bodo’s SPMD execution model, on the other hand, is a better fit for the all-to-all pattern as communication is embedded directly in collective execution. Shuffles are implemented with asynchronous point-to-point MPI communication and can leverage GPUDirect technologies for zero-copy GPU-to-GPU transfers. Bodo also streams batches of data through pipelines of operators, reducing the need to materialize large intermediate results between stages while requiring fewer synchronization points.
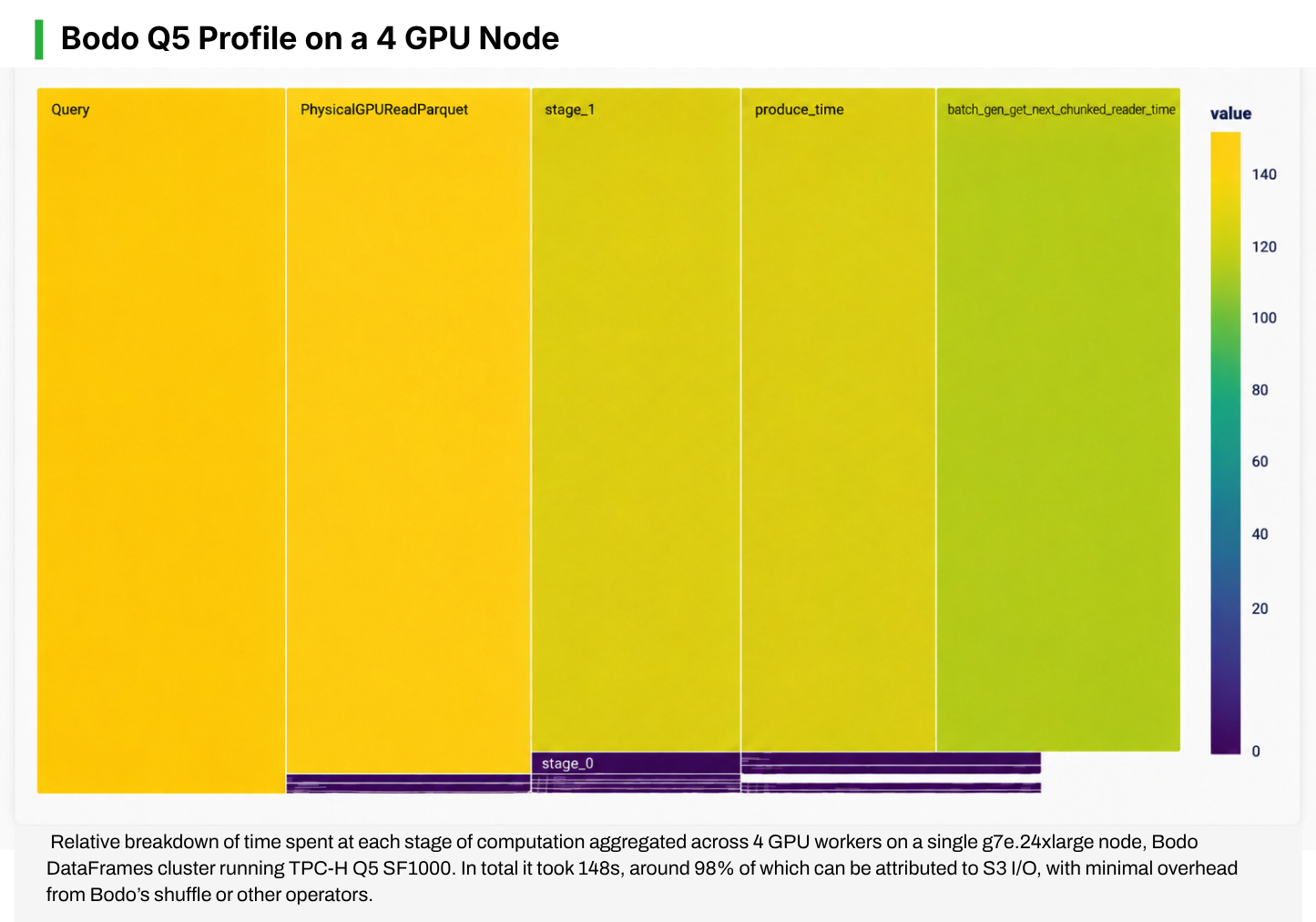
I/O was another contributor to runtime and is often a dominant factor in real-world analytical workloads, particularly when datasets are fragmented across many small files. Our SF1000 dataset consisted of more than 13,000 parquet files, with most files smaller than 50 MB. Although both Bodo and Dask-CuDF rely on the same libcudf kernels for parquet decoding and filtering, Bodo issues fewer metadata requests to cloud object stores such as S3 by using metadata sampling techniques rather than scanning metadata for every file individually.
Finally, it is important to note which factors did not significantly contribute to the observed performance differences. Both Bodo and Dask-CuDF rely on the same underlying libcudf GPU kernels for operations such as joins, aggregations, filtering, and parquet decoding, so differences in low-level GPU kernel performance is not a factor in the results. Both systems also apply standard query optimizations including filter pushdown and column pruning. While Bodo’s optimizer performs additional optimizations such as join reordering, which can make a significant difference in more complex cases, profiling indicated that the largest differences came from distributed execution, I/O, and communication overhead rather than better query plans.
Both systems were given a cluster consisting of 4 nodes with 2 GPUs, similar to the multi-node setting from the previous post:
Bodo was run on an EFA-enabled EC2-cluster with AWS Deep Learning AMI (Deep Learning Base AMI with Single CUDA (Amazon Linux 2023) 20260424). In this setup, Bodo was built with CUDA Aware MPICH-MPI 5.0, due to issues with CUDA-Aware OpenMPI provided by Conda-Forge in multi-node environments.
Dask-CuDF was run using a typical EC2 cluster deployment. Dask-CloudProvider was used to launch a scheduler along with 4 worker instances from the client’s machine (client was an EC2 instance in the same region as the cluster). To simplify deployment, the scheduler was the same instance type as the workers, although it did not participate in the computation.
The scale factor (SF) in TPC-H controls the size of the generated dataset by scaling the number of rows in the variable-sized tables. For example, the largest table, lineitem, contains approximately 6 million rows at SF1 and roughly 6 billion rows at SF1000. The data for each scale factor is generated synthetically using the official TPC-H dbgen tool, then converted from CSV into parquet format using a separate preprocessing script. The final parquet dataset for SF1000 totaled around 1000GB uncompressed / 390 GB compressed and is available in a public bucket at s3://bodo-example-data/tpch/SF1000.
For each benchmark, we executed every query once and measured end-to-end runtime, including S3 I/O. As in our previous benchmarks, we focused on “out-of-the-box” configurations and avoided extensive manual tuning beyond settings recommended in the official setup and best practices documentation. This approach is intended to reflect the experience of a typical user without deep system-specific expertise while avoiding benchmark-specific overfitting. Code for reproducing the benchmark can be found here.
Since our previous GPU blog, Bodo DataFrames has added more GPU-capable operators including:
Overall, the results show that parallel architecture plays a major role in large-scale GPU dataframe workloads. Across the full TPC-H suite, Bodo consistently outperformed Dask-CuDF— achieving 3x faster combined performance across the 22 queries—with the largest gains occurring on queries dominated by large joins and aggregations, all while relying on the same underlying libcudf kernels.
These results highlight the advantages of an MPI-based SPMD execution model for communication-intensive analytical workloads. By executing a single distributed program collectively across all workers, Bodo is able to perform peer-to-peer and collective communication more efficiently than a task-based execution model. The results also indicate the importance of efficient metadata lookup when it comes to reading a large number of files from cloud storage. As GPU compute performance continues to improve, the efficiency of distributed communication, data movement, and I/O are becoming increasingly important factors in end-to-end DataFrame performance.





