
%20(1200%20x%20485%20px).png)


While GPUs offer massive parallelism and memory bandwidth, achieving real end-to-end performance on GPU clusters is challenging—it requires carefully minimizing data movement (especially costly GPU↔host transfers), eliminating unnecessary work, and coordinating execution seamlessly across CPUs and GPUs at scale. We built GPU acceleration into Bodo DataFrames to tackle this challenge head-on. By combining a database-grade optimizer, streaming execution, and an efficient HPC-style distributed runtime, Bodo optimizes and executes entire workloads across nodes and devices, maximizing performance while minimizing overhead.
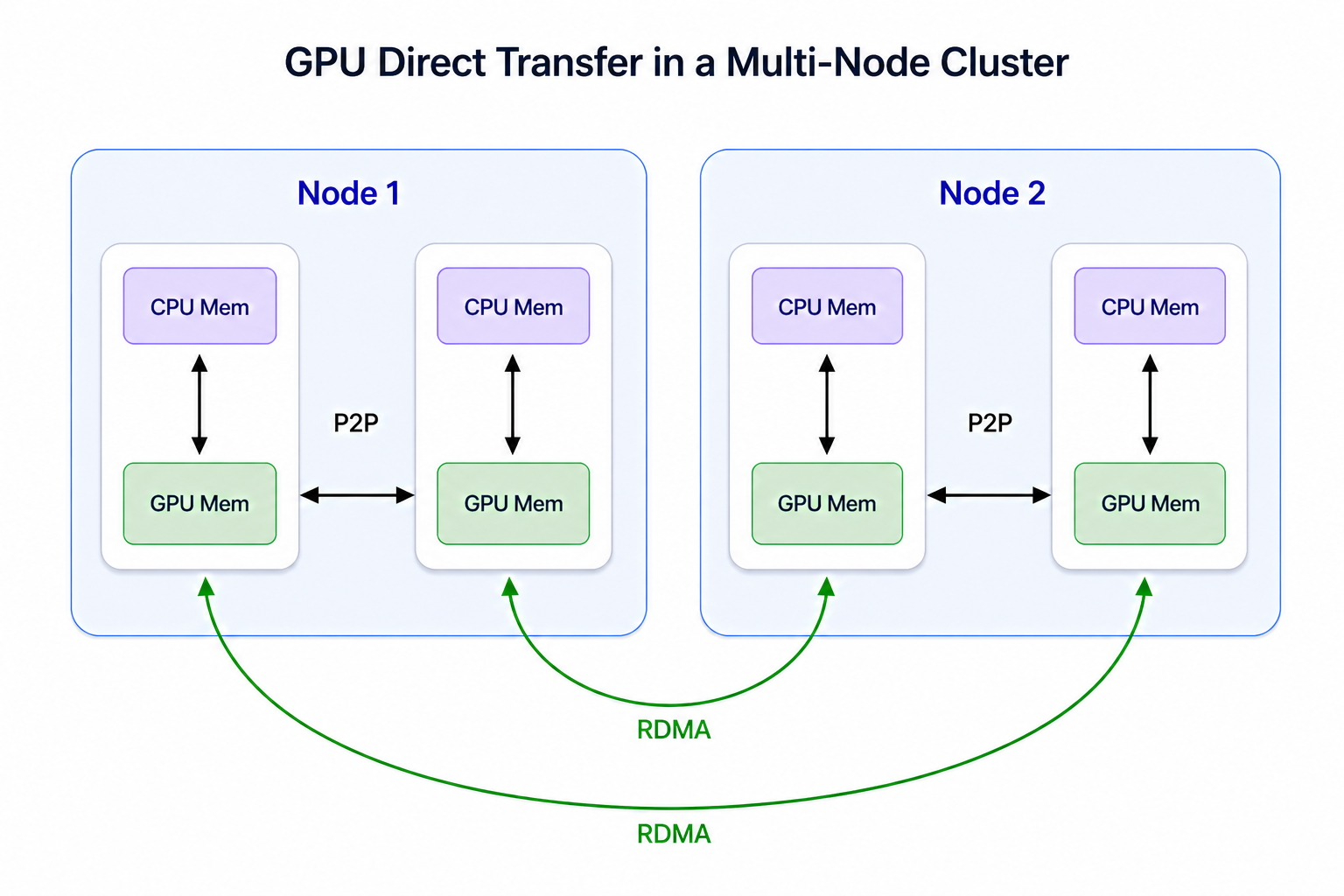
The key advantage of Bodo over GPU DataFrame systems like Dask-cudf lies in its Single Program, Multiple Data (SPMD) execution model built on MPI. In this model, workers execute the same program independently while remaining fully aware of one another, enabling direct, peer-to-peer and collective communication without relying on a central coordinator. In contrast, task-based runtimes like Dask depend on a centralized driver to orchestrate execution (except limited p2p workarounds), introducing high overhead from task management and coordination. This difference becomes especially pronounced on GPUs, where task-based systems often incur costly GPU↔host transfers and coordination overheads, leading to underutilized GPU hardware. Bodo’s SPMD architecture avoids these bottlenecks by minimizing coordination overhead and enabling efficient GPU-to-GPU communication via GPU Direct P2P and RDMA, resulting in efficient parallel execution and much better overall GPU utilization.
In this post, we’ll:
For this preview of GPU acceleration in Bodo DataFrames, we selected TPC-H query 5 (example code below) for its common mixture of joins, filters, column expressions, and aggregations. We use TPC-H scale factor 1000 data stored on S3. More details on how Bodo works internally and utilizes GPUs are in the following sections. To give a quick snapshot of performance across environments, the table below summarizes results for TPC-H Query 5:
Configuration:
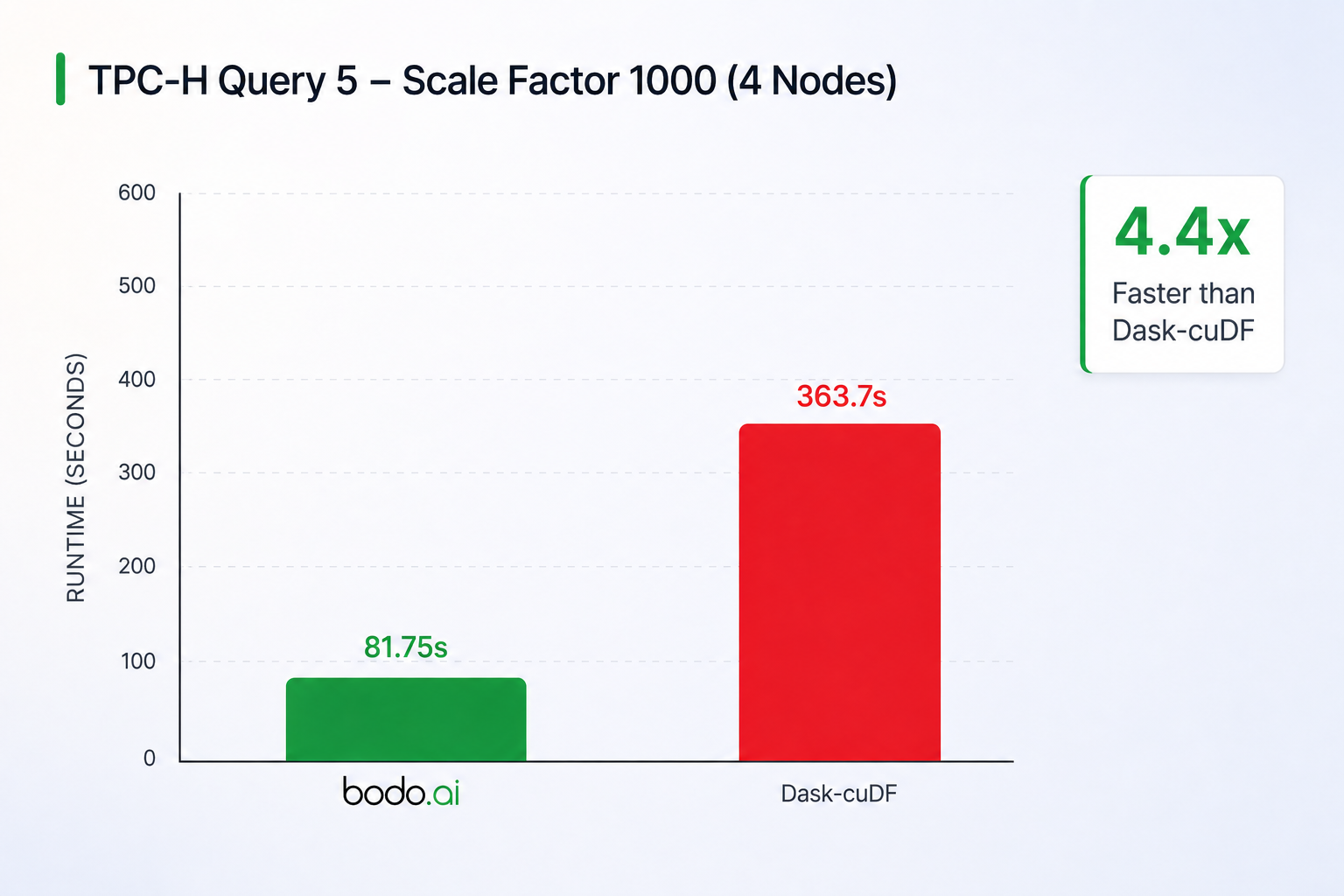
Bodo is over 4x faster than Dask-cuDF and has near linear scaling when compared to the single-node, 4 GPU configuration below. Dask-cuDF suffers from slow shuffles since it writes communication data to files instead of direct transfers, causing costly GPU↔host transfers and other overheads. This is due to its task-based architecture where tasks cannot communicate with each other directly (except limited workarounds that go against the architecture). On the other hand, Bodo’s SPMD architecture allows the use of GPU Direct P2P and RDMA, where GPUs access each other’s memory across the cluster directly without overheads like transfers to the host. Furthermore, Bodo loads data from S3 to GPUs much faster than Dask.
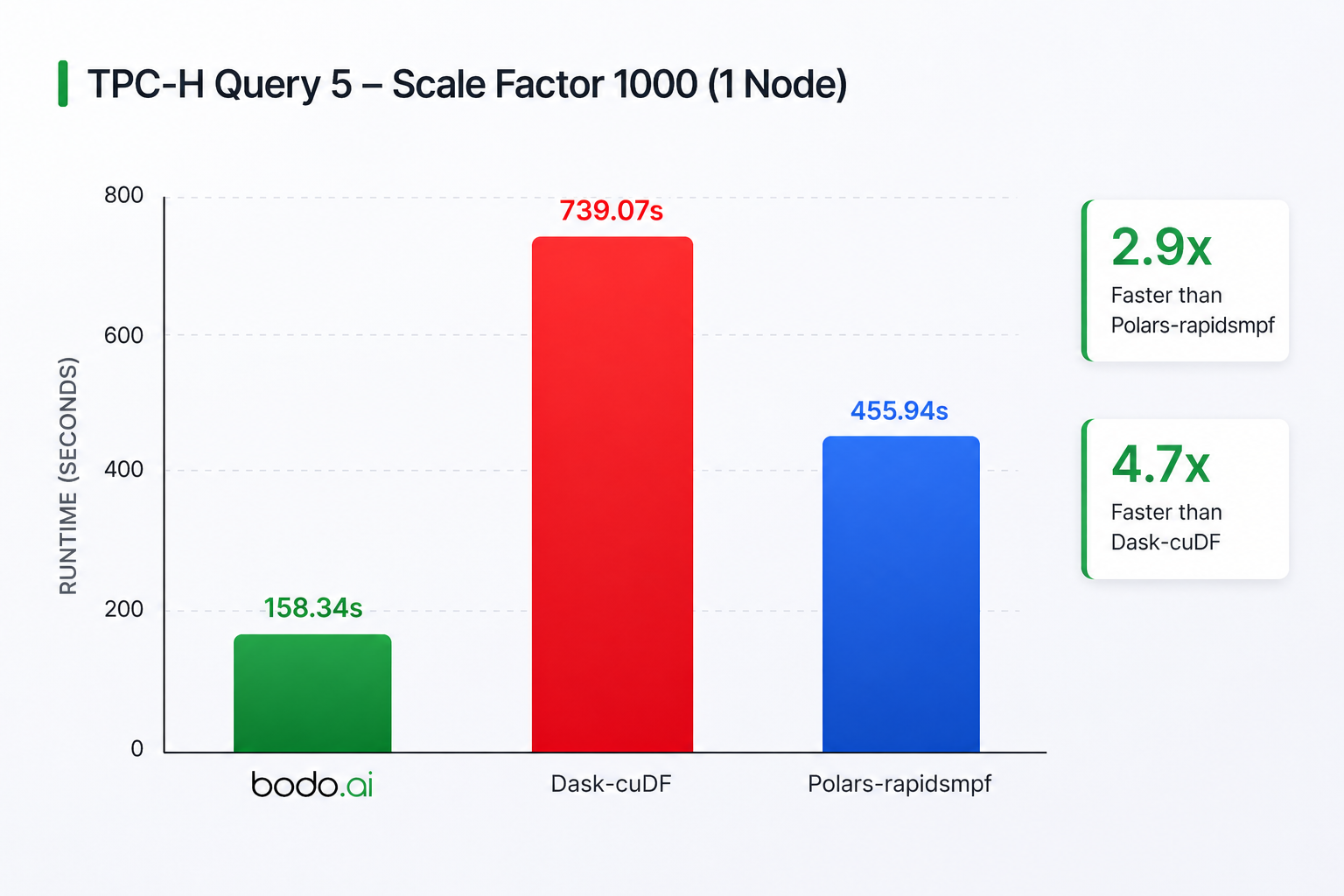
In this configuration, Bodo is 4.5x faster than Dask-cudf and 2.9x faster than Polars. Dask-cuDF’s performance issues are similar to above. In this case, we believe the Polars-rapidsmpf’s performance difference with Bodo is attributable to the I/O performance differences (probably insufficient number of I/O threads in Polars) since the program loads large data from S3. Nevertheless, these results demonstrate Bodo’s efficiency on a single node as well.
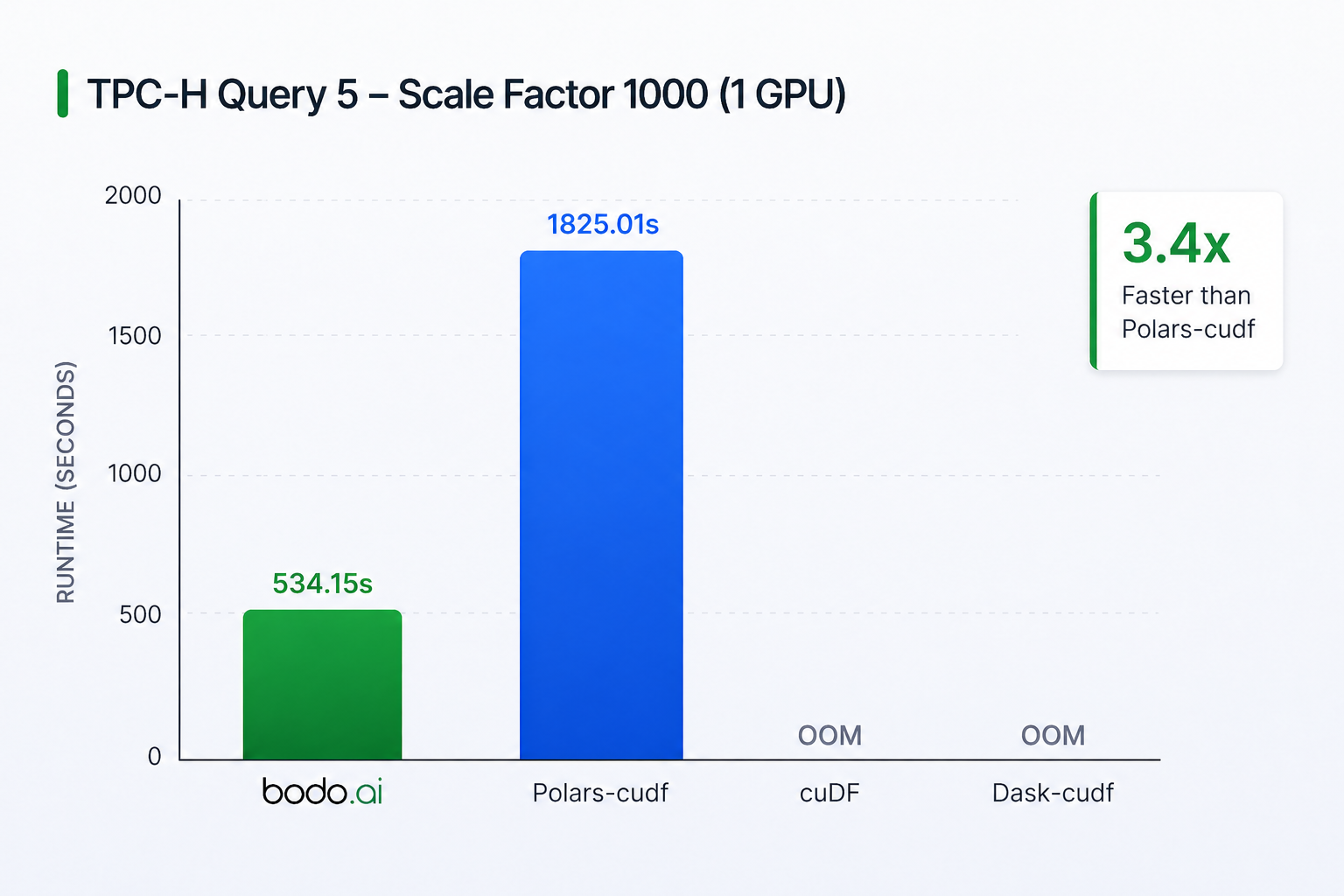
Both Dask-cuDF and cuDF ran out of memory and were unable to complete the benchmark. This demonstrates the importance of Bodo’s streaming execution to avoid memory issues especially with limited GPU memory. Bodo is 3.4x faster than Polars again due to limited I/O bandwidth. Overall, these results demonstrate Bodo’s efficiency even on a single GPU.
This table summarizes the capabilities of different GPU DataFrame systems (more details below):
Our testing methodology for Bodo and the other systems was to try to replicate a typical user experience where the software is installed and some minimal configuration settings from a getting started page are applied. As such, no in-depth configuration tuning was performed for any of the systems. All the code and scripts to replicate the following results for Bodo and the other systems can be found at https://github.com/bodo-ai/Bodo/tree/main/benchmarks/gpu/tpch.
For this particular query in the current Bodo DataFrames, all of the operations from the initial loading of data from parquet files up to and including the groupby are run on GPU. We don’t support dataframe sorting on GPU yet (coming soon), so the sorting and collecting of batches to form a complete dataframe are performed on CPU but the data is small at that stage and this doesn’t affect performance.
TPC-H Query 5 Bodo source code below.
def tpch_q05(lineitem, orders, customer, nation, region, supplier):
var1 = "ASIA"
var2 = datetime.date(1996, 1, 1)
var3 = datetime.date(1997, 1, 1)
jn1 = region.merge(nation, left_on="R_REGIONKEY", right_on="N_REGIONKEY")
jn2 = jn1.merge(customer, left_on="N_NATIONKEY", right_on="C_NATIONKEY")
jn3 = jn2.merge(orders, left_on="C_CUSTKEY", right_on="O_CUSTKEY")
jn4 = jn3.merge(lineitem, left_on="O_ORDERKEY", right_on="L_ORDERKEY")
jn5 = jn4.merge(
supplier,
left_on=["L_SUPPKEY", "N_NATIONKEY"],
right_on=["S_SUPPKEY", "S_NATIONKEY"],
)
jn5 = jn5[jn5["R_NAME"] == var1]
jn5 = jn5[(jn5["O_ORDERDATE"] >= var2) & (jn5["O_ORDERDATE"] < var3)]
jn5["REVENUE"] = jn5.L_EXTENDEDPRICE * (1.0 - jn5.L_DISCOUNT)
gb = jn5.groupby("N_NAME", as_index=False)["REVENUE"].sum()
result_df = gb.sort_values("REVENUE", ascending=False)
return result_df
To understand how GPU acceleration has been integrated with Bodo, it is helpful to understand the overall Bodo DataFrames architecture. Bodo’s dataframe library consists of three major components: plan capture → plan optimizer → plan execution. We have made significant changes to physical plans and plan execution to support CPU-GPU hybrid execution. All of the Bodo DataFrame components except for plan capture use all available CPUs and GPUs in the system (single-node or cluster) via MPI. There is one MPI rank for each available CPU and for convenience we will refer to these as CPU ranks. For each GPU on a given node, a CPU rank will be selected as that GPU’s proxy and these selected CPU ranks will also be called GPU ranks.
Bodo DataFrames implements the Pandas API and these Pandas operations are intercepted and represented as operations in a logical query plan. Bodo continues building this query plan lazily until execution is required. Execution is triggered when the output of an operation produces data (e.g., Python scalars, output files, etc.) not controlled by the library. At that point, Bodo prepares the query plan for execution:
Plan construction itself happens only on the main process (the process running the user’s Python program). The resulting relational plan is then broadcast to all workers via MPI, and every worker executes the same optimized plan in parallel across partitions of the data.
Bodo DataFrames uses an advanced query optimizer that has database-grade capabilities. It transforms naïve logical plans into highly efficient execution strategies through a rich set of rule‑based and cost‑based optimizations, including predicate pushdown, join reordering, column pruning, and set‑operation rewrites. By leveraging detailed column‑ and table‑level statistics, it can make join and filter decisions with precision, often matching or exceeding the performance of hand‑tuned SQL in other engines.
Bodo uses a “push-based” model for query execution (similar to databases such as Snowflake). The optimized logical plans (with dependencies between operators) are converted to physical pipelines (with dependencies between pipelines) which can then be scheduled and executed. These pipelines are themselves composed of sequences of physical operators. With the introduction of CPU-GPU hybrid execution, this phase must also decide whether each of these physical operators will run on CPU or GPU. Currently, we use the basic strategy of running everything on GPU for which we have an implementation. See the supported operators section below for a description of what we currently support on GPU and the roadmap section for future work that will identify cases where running an operator on CPU may be faster than GPU.
Pipelines are executed according to their data dependencies. The pipelines in the pipeline DAG are scheduled in topological order. Any pipeline whose upstream dependencies are satisfied becomes ready and can be scheduled for execution. Within each pipeline, execution is streaming with batches of rows flowing through operators:
This execution strategy enables multi‑node parallelism and out‑of‑core execution so that datasets far larger than the cumulative CPU or GPU memory of the machine or cluster can be processed.
In the following sections, we dive deeper into how this execution model interacts with GPU operators, as well as how data is transferred efficiently between CPU and GPU and across GPUs in distributed environments.
When consecutive nodes in a pipeline are both executed on GPU, Bodo keeps the batch data entirely in GPU memory and passes a libcudf table between those nodes. Each GPU pipeline operator:
These operators vary in complexity with some being thin wrappers around a libcudf operation while others involve significant orchestration across multiple libcudf kernels or MPI ranks with multiple libcudf operations as expounded in the next section.
Pipeline operators come in two varieties: local-based and collective-based. Local-based operators do not need to communicate with corresponding operators running on different MPI ranks but collective operators do. For GPU collective operators, we use GPU-aware MPI implementations with GPUDirect P2P or RDMA to transfer data directly between GPU memories when possible. Again, we then use libcudf operators to operate on the data once it has been received. All data transfers are performed asynchronously (e.g. using MPI_Issend) so additional batches can flow through the local-based portion of the pipeline while waiting for the transfers to complete and in this way maximizing the overlap between computation and communication.
Data is passed through the pipelines in batches of rows but the optimal batch size for CPU and GPU is different. The size, structure and properties of CPU caches tends to favor a smaller batch size whereas GPUs tend to prefer much larger batch sizes. Since the same pipeline can contain CPU and GPU operators, our pipeline must handle batch size adaptation as we switch between CPU↔GPU execution. The next section describes how this adaptation is performed.
When consecutive nodes in a pipeline are running on different devices, Bodo automatically manages the communication of the data between host and device. The following diagram depicts this process through Pandas code that uses a user-defined function (UDF) which runs on CPU while the code before and after the UDF runs on GPU. The right-side of the diagram shows the equivalent optimized Bodo plan with orange boxes added to make clear where Bodo is handling CPU to GPU communication.
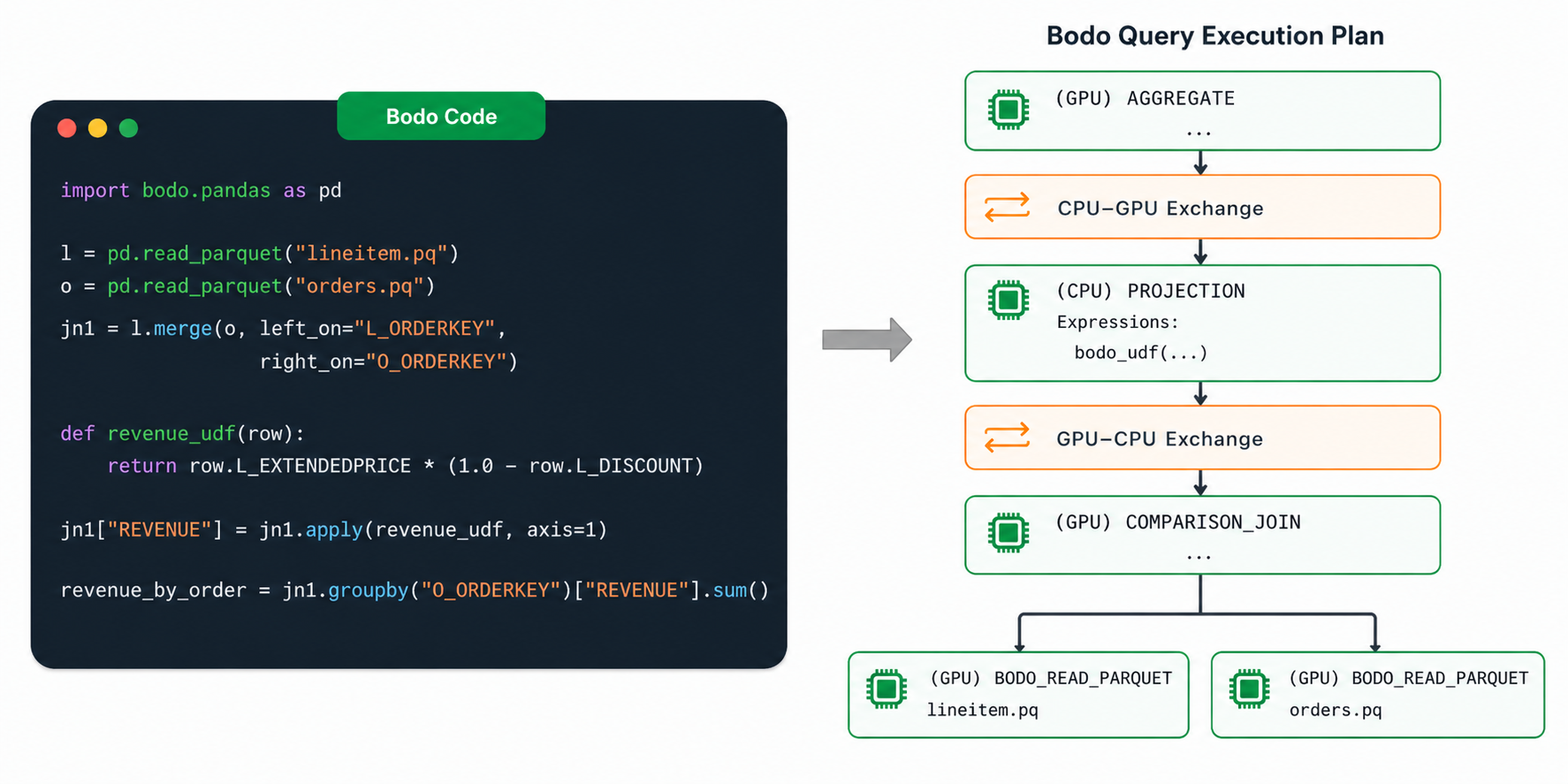
In the CPU to GPU direction, as the smaller CPU batches finish the CPU operator, they are sent asynchronously to the GPU. In effect, the first portion of the pipeline up to this CPU operator will run multiple times and initiate multiple asynchronous data transfers to the GPU. Once the GPU has received enough such transfers that the accumulated data exceeds the GPU batch size then a singular libcudf table is made from those parts and given to the next GPU operator in the pipeline for processing.
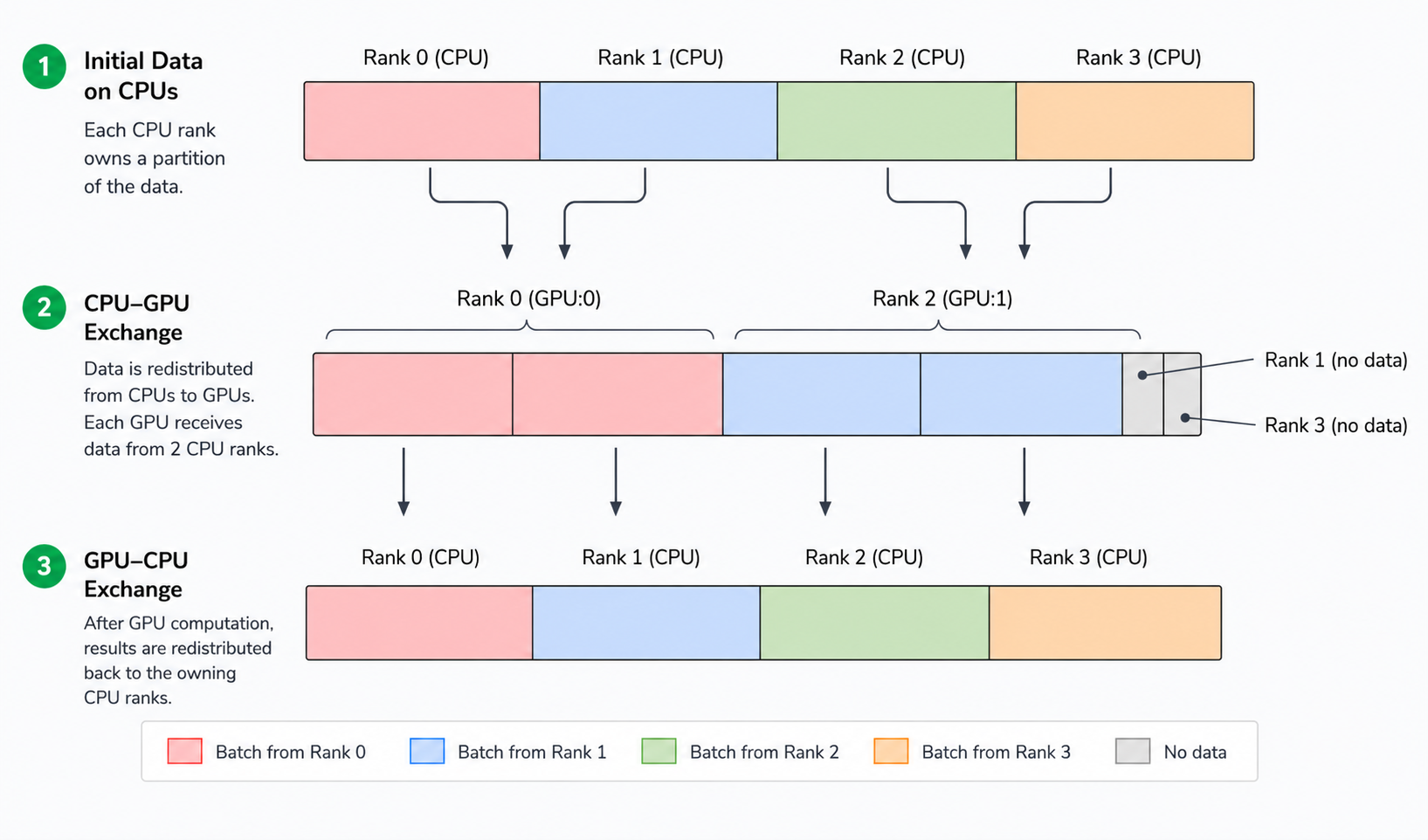
However, because it is typical for there to be many more CPU ranks than GPU ranks, it does not normally happen that a single CPU rank sends data to a GPU rank. Instead, Bodo partitions the CPU ranks, with a distinct subset of CPU ranks associated with each GPU rank. For example, an 8 CPU core, 2 GPU system might have CPU ranks 0-3 associated with GPU 0 and CPU ranks 4-7 associated with GPU 1. Here, CPU ranks 0 and 4 will also be GPU ranks and act as proxies (i.e., initiating kernels, memory transfers, etc) for GPU activities for GPUs 0 and 1 respectively. As above, when a CPU operator precedes a GPU operator in a pipeline, all the CPU ranks associated with a given GPU rank will first send their data to that GPU rank and the GPU rank will initiate the asynchronous transfers and form the libcudf table when those transfers are complete.
If the node following a GPU node in a pipeline is a CPU node then the process is reversed. The Bodo pipeline will split the GPU-sized batch into CPU-sized parts and initiate asynchronous transfers for each of those parts to the associated CPU ranks. As each of those parts are received by the CPU ranks then that CPU portion of the pipeline on those CPU ranks is able to continue executing. This asynchronous transfer approach allows us to overlap computation and communication to the greatest degree possible.
The following diagram depicts this process on a 4 CPU core, 2 GPU system where there is a CPU operator followed by a GPU operator followed by another CPU operator. CPU ranks 0 and 1 are associated with GPU 0 and CPU ranks 2 and 3 associated with GPU 1. Two CPU batches come from those CPU ranks to form one GPU batch and the output of the GPU operator is split into two CPU batches.
Eager GPU libraries like cuDF are excellent at single‑operator throughput but lack whole‑query, cross‑operator optimization. Bodo’s lazy API + optimizer provides these decisive advantages:
By processing data as a stream of batches, Bodo DataFrames is able to efficiently utilize the respective properties of CPU and GPU architectures such as caches and avoid running out of memory as much as possible. This is especially important for GPUs which have limited memory.
As explained above, Dask-cuDF and Polars-rapidsmpf are fundamentally task-based runtimes with a single, central coordinator process, which is inherently less efficient than Bodo’s HPC-style, single-program, multiple data (SPMD) execution with MPI.
Polars-rapidsmpf is currently limited to single-node operation and does not support the multi-node scaling required to utilize the 4-node, 8-GPU cluster configuration used in our larger benchmark. In contrast, Bodo’s unified architecture is engineered for full data parallelism across heterogeneous multi-node clusters, allowing it to scale effectively on any number of CPUs and GPUs.
bash
conda install -c bodo.ai -c rapidsai -c nvidia bodo=*=*cuda --no-channel-prioritybash
export BODO_GPU=1Currently, the following environment variable must be set for OpenMPI to use UCX for the communication layer, but we intend to do this automatically in the near future and remove the need for this to be set explicitly.
bash
export OMPI_MCA_pml=ucxbash
export BODO_DATAFRAME_LIBRARY_DUMP_PLANS=1
Bodo DataFrames delivers GPU acceleration by fundamentally rethinking how distributed execution should work in a GPU setting. While many systems rely on task-based runtimes, Bodo’s core advantage comes from its SPMD architecture built on MPI. By eliminating the need for a centralized scheduler, Bodo allows workers to execute in lockstep and communicate directly using efficient peer-to-peer and collective operations. This is critical for GPUs, where avoiding coordination overhead and unnecessary GPU↔host transfers is often the difference between high utilization and idle hardware.
This architectural choice enables capabilities that are difficult to achieve in task-based systems: efficient GPU-to-GPU communication via GPUDirect P2P and RDMA, better overlap of computation and communication, and scalable performance across nodes without the bottlenecks of centralized orchestration. Combined with Bodo’s database-grade optimizer and streaming execution model, SPMD ensures that not only is less work performed, but that the remaining work is executed as efficiently as possible across the entire cluster.
Our early results—over 4× faster than Dask-cuDF and close to 3× faster than Polars on GPU—highlight the impact of this approach. As we continue to expand GPU support and introduce features like device placement optimization, we believe SPMD will remain the foundation that allows Bodo to fully realize the potential of GPUs for large-scale DataFrame workloads.





