June 4, 2026
isaac-warren
Apache Iceberg substantially alters how distributed execution engines interact with storage. Instead of relying on fragile directory listings, Iceberg overlays a transactional metadata layer, using explicit manifests to track the exact state of a table at a specific snapshot. For a query engine planner, this is a massive operational upgrade that provides efficient partition pruning, atomic commits, and robust logical schema evolution. But while Iceberg brings strict order to the logical planning phase, it pushes a significant amount of complexity down into the physical execution layer.
When you write a query over Apache Iceberg tables, the catalog promises you a clean, unified logical schema. But when you actually traverse the object store, the physical reality is chaotic. Files written two years ago have different column types than files written yesterday. Fields have been dropped, renamed, or buried three levels deep inside a nested struct.
For a distributed, GPU-native streaming execution engine, this physical chaos is a severe performance challenge. GPUs achieve their massive throughput by exploiting massive parallelism over rigid, predictable columnar structures (like cuDF or Arrow vectors). They expect uniform memory strides and deterministic bit-widths. If you naively pass a batch of heterogeneous Parquet files to a hardware-accelerated chunked reader, a sudden type variance, like an evolved INT32 to INT64 or a newly appended struct field, will break memory alignment rules and immediately panic the execution stream. Furthermore, materializing unoptimized, pre-filtered data into tight memory budgets is a guaranteed way to out-of-memory (OOM) an expensive cluster of GPUs.
To solve this, we built a GPU-native Iceberg source operator that acts as a defensive shock absorber between raw storage and our execution pipeline. Rather than forcing the downstream engine to deal with unpredictable streams, this operator isolates the physical variance of the data source entirely.
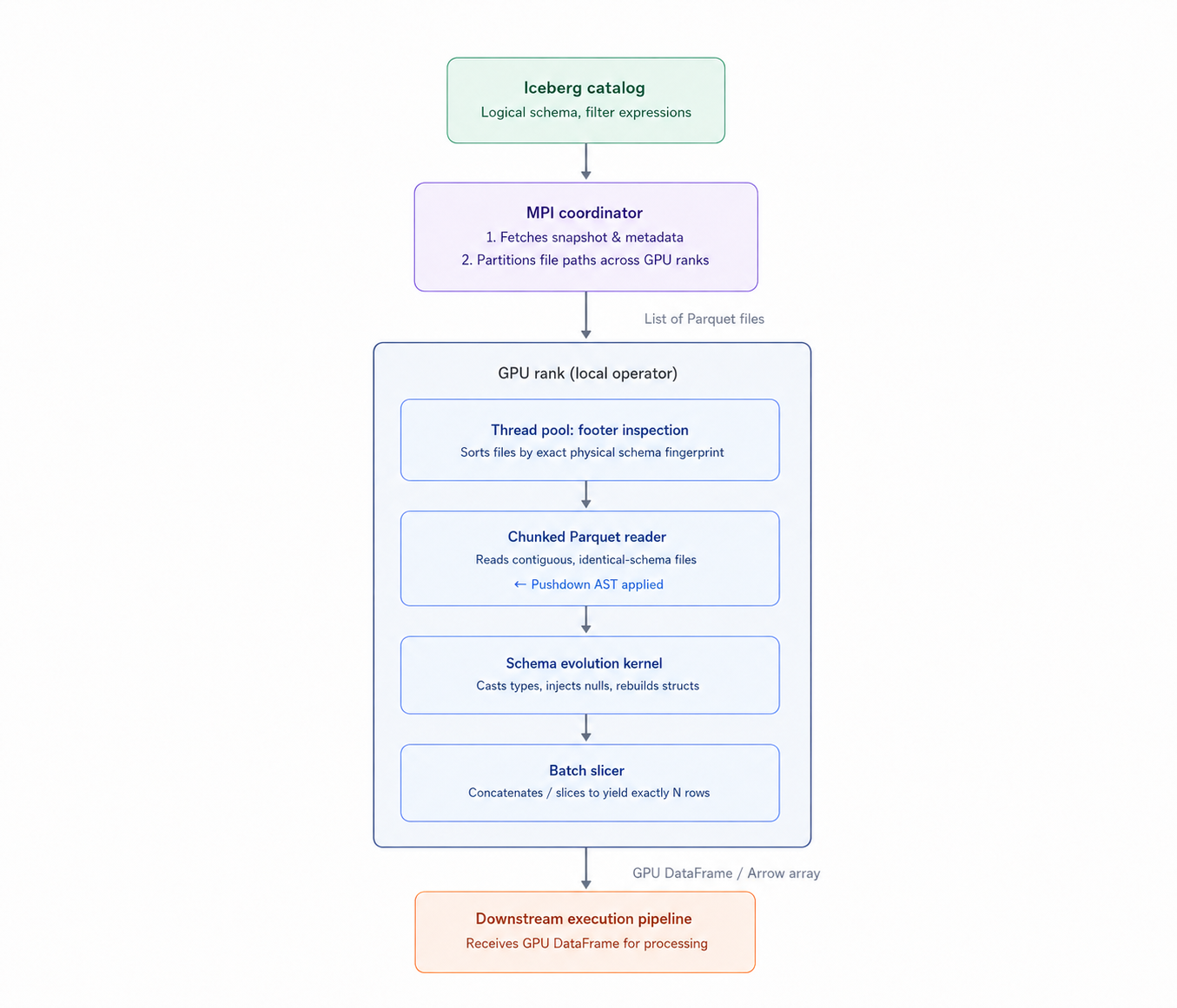
Architecturally, it coordinates across MPI ranks to manage data ingestion through three core phases:
Here is a deep look into how we designed this operator, the architectural tradeoffs we weighed, and the specific edges we encountered while making the storage layer safe for hardware acceleration.
To the end user, reading an Iceberg table into a distributed pipeline looks completely benign. They interact with a clean, high-level DataFrame abstraction using accelerated Pandas APIs:
When this Python code triggers execution, the user assumes a clean, uniform matrix of data is streaming into memory. They have no idea that beneath this two-line abstraction, the engine is tracking shifting schema groups, variable column indices, and type mismatches.
Here is what actually happens when that plan is unpacked by the physical execution layer.
At a high level, the operator is a distributed batch generator. It coordinates across MPI ranks to partition the dataset, streams data into the GPU using chunked Parquet readers, normalizes the physical data to match the logical schema, and yields strict, predictable row-count batches to the downstream engine.
When a query plan hits this operator, the engine expects an iterative operator call that returns a GPU-resident table and a boolean indicating if the stream is exhausted.
Because downstream operators (like joins or aggregations) expect predictable memory pressure, we enforce a strict target_rows limit per batch. If our chunked reader yields 150,000 rows but the target is 100,000, we slice the GPU table, yield the 100,000, and hold the remaining 50,000 as a leftover_tbl in device memory for the next iteration. If the reader yields 20,000 rows, we accumulate them in a vector until we hit the threshold, executing a single GPU concatenation kernel before yielding.
This decoupling of read-chunk size from yield-batch size is critical for pipeline stability, but the real complexity lies in how we feed the reader.
Cudf’s GPU Parquet reader is highly optimized, but it expects uniformity. To saturate memory bandwidth, you typically use a "chunked" reader, feeding it dozens of file paths at once. But in Iceberg, schema evolution means File A might have user_id as an INT32, while File B (written after a schema evolution) has user_id as an INT64. If you pass both files into the same chunked reader instance, it will fail when attempting to allocate a contiguous columnar buffer.
Options:
We opted for dynamic reader grouping using what we call "physical schema fingerprints."
Unfortunately, Iceberg Schema groups alone weren’t enough to group files. When we initially tried this we still got schema mismatch errors from the reader. To solve this the operator spins up a CPU thread pool sized to the host's IO capacity during the initialization phase. These threads asynchronously fetch the Parquet footers for all files assigned to the rank. For every column required by the query (both selected columns and filter columns), we extract its physical type, converted type, logical type, and repetition/definition levels.
We flatten this metadata into an integer vector, a fingerprint for each file.
We then sort the rank's assigned files first by their Iceberg schema group, and then by their physical fingerprint. When the iteration starts, the operator spins up a chunked reader for a contiguous block of identically-fingerprinted files. The moment the fingerprint changes, we flush the reader, yield the batch, and initialize a new reader for the next schema configuration. This guarantees the GPU reader never chokes on a type mismatch, while still maintaining high batch throughput.
Filtering data after it lands in GPU memory is too late; you've already paid the I/O and memory allocation costs. We need to push filters down into the Parquet decode phase. However, our query planner speaks DuckDB's expression language, while Iceberg's metadata uses its own partition filtering logic. Worse, the column indices change across files. user_id might be column index 3 in one file, and column index 5 in another.
Before we even worry about row-level GPU filtering, we have to prevent irrelevant files from crossing the network in the first place. The query planner hands us a set of filters describing the query's constraints, but Iceberg’s metadata evaluation relies on its own expression tree (via PyIceberg) to do partition pruning. To bridge this, we built a traversal layer that translates DuckDB’s internal filter representation directly into PyIceberg filter objects. We then logically AND these translated predicates with any native Iceberg filters attached to the read. By feeding this combined expression back into the catalog during the initial dataset fetch, we prune the file list at the manifest level meaning the GPU only ever provisions readers for files that have a chance of containing relevant data.
Once we’ve pruned the files, we still have to filter the actual rows. Evaluating predicates after the data lands in GPU memory wastes PCI-e bandwidth and VRAM; the filtering has to happen on the device during Parquet decompression. To do this, we translate the combined DuckDB and PyIceberg constraints into a cuDF Abstract Syntax Tree (AST) that the hardware can evaluate as it reads.
The tricky part here is variable binding. Because of schema evolution, we can't hardcode column indices into the AST. user_id might be column 3 in today's files but column 5 in last year's. Instead, we anchor everything to Iceberg's immutable field ids. Before dispatching a group of files to the chunked reader, we dynamically construct the AST, mapping the field id to the physical local column index of that specific file group.
This mapping also gives us an elegant way to handle missing columns. If the query filters on a field that physically doesn’t exist in an older file, a naive reader would crash trying to reference it. Instead, we intercept the missing field id during AST generation and inject an identity scalar false node into the tree. The GPU essentially treats the missing column as NULL, short-circuits the AST evaluation, and efficiently drops the rows without ever attempting to read non-existent data.
Iceberg schema evolution is relatively straightforward for top-level primitive types (e.g., casting FLOAT to DOUBLE). But what happens when a user adds a new key-value pair to a deeply nested map, or appends a field to a struct inside a list?
The GPU memory layout for nested types uses strict offset arrays and child buffers. If a file is missing a nested field, we must reconstruct the entire columnar hierarchy in device memory before yielding it to the downstream engine, otherwise, vector operations will read garbage memory.
We solve this using recursive column reconstruction driven by Iceberg field IDs.
After a batch is read, we pass it through an evolve_table kernel. For complex types (Structs, Lists, Maps), the evolution function calls itself recursively. It unpacks the raw memory contents of the column (releasing the null mask and child arrays).
If the target schema dictates a struct needs a child field that isn't present in the source struct, we generate a null array of the exact row length. We then interleave this newly allocated null column into the vector of existing child columns, taking care to preserve the parent's null mask. Finally, we repack the offset arrays and return a newly constructed struct column that perfectly matches the engine's expected memory layout.
By doing this immediately after the chunked read (and before batch concatenation), we keep the working set size small and predictable.
From the perspective of the broader query engine, this complexity is completely hidden. The operator participates in the standard physical plan lifecycle.
Here is a simplified look at how a downstream execution node or test harness would consume this operator:
The consumer doesn't know about physical Parquet files, chunk sizes, or schema evolution. It simply asks for data and receives uniformly formatted, pre-filtered GPU DataFrames.
There are various aspects of the reader that we plan to improve in the future:
1. Support Iceberg V2 deletes (positional/equality): Currently, this source operator focuses entirely on data file reads. It does not natively merge Iceberg delete files inside the Parquet reader kernel.
2. Reduce metadata latency: on Cloud Stores Our physical schema fingerprinting relies on reading the Parquet footers of all assigned files before yielding the first batch. If a query hits a massive, un-partitioned table with 200,000 Parquet files on S3, the latency of issuing 200,000 GET byte-range requests from the CPU thread pool can take several seconds, delaying the first time-to-byte on the GPU.
3. Reduce VRAM spikes via compression: We use Iceberg metadata to estimate the uncompressed byte size of a file, which dictates how many files we feed into a single chunked reader to avoid OOMs. However, Parquet compression ratios can vary wildly. A highly repetitive dictionary-encoded column might expand by 50x in GPU memory, occasionally causing memory pressure spikes that exceed our chunk limits.
4. Reduce reader overhead: Creating a new cudf reader comes with a cost. In the future we could distribute files across ranks such that matching physical schemas are likely to end up on the same rank to mitigate this overhead.
The real challenge of this was unifying the physical chaos of the object store without OOMing the GPU or panicking the execution stream. You can't just throw a standard JVM or Python catalog library at the problem when you're managing tight VRAM budgets and hardware-accelerated kernels. You have to handle the mess directly on the device.
Getting this right reinforced something we've learned the hard way: your downstream pipeline is only as fast as its source operator. If you have to bounce back to the CPU to handle a dropped column, pad a nested struct, or evaluate a missing filter, you've already lost performance before the query really begins.
To get started using Bodo yourself:




