Bodo gives teams a modern foundation for analytics in the AI era — where business users, data teams, and agents can work in the languages and tools they already know, with the trust and performance their enterprises require.


Open and modular
Built on open source foundations under the Apache 2.0 license.
Works with your stack
Keep the languages and workflows your teams already know.
Built-in governance
Keep analytics workflows governed, validated, and under enterprise control.
Performance at scale
Accelerate analytics and AI workflows from question to execution.
Open and modular
Built on open source foundations under the Apache 2.0 license.
Works with your stack
Keep the languages and workflows your teams already know.
Built-in governance
Keep analytics workflows governed, validated, and under enterprise control.
Performance at scale
Accelerate analytics and AI workflows from question to execution.

The most accurate, secure, and verifiable answer layer for enterprise AI—enabling anyone to safely turn their enterprise data into trusted answers.

Bodo Engine gives data teams the performance of a distributed compute engine with the simplicity of the tools they already know. Run Pandas, Python, and SQL across CPUs and GPUs — with no data migration, no workflow changes, and no code changes.
Faster than Polars multi-GPU
Faster 3× than Dask-CuDF
The latest and greatest benchmarks, comparisons, use cases, and other product news from the Bodo engineering team.
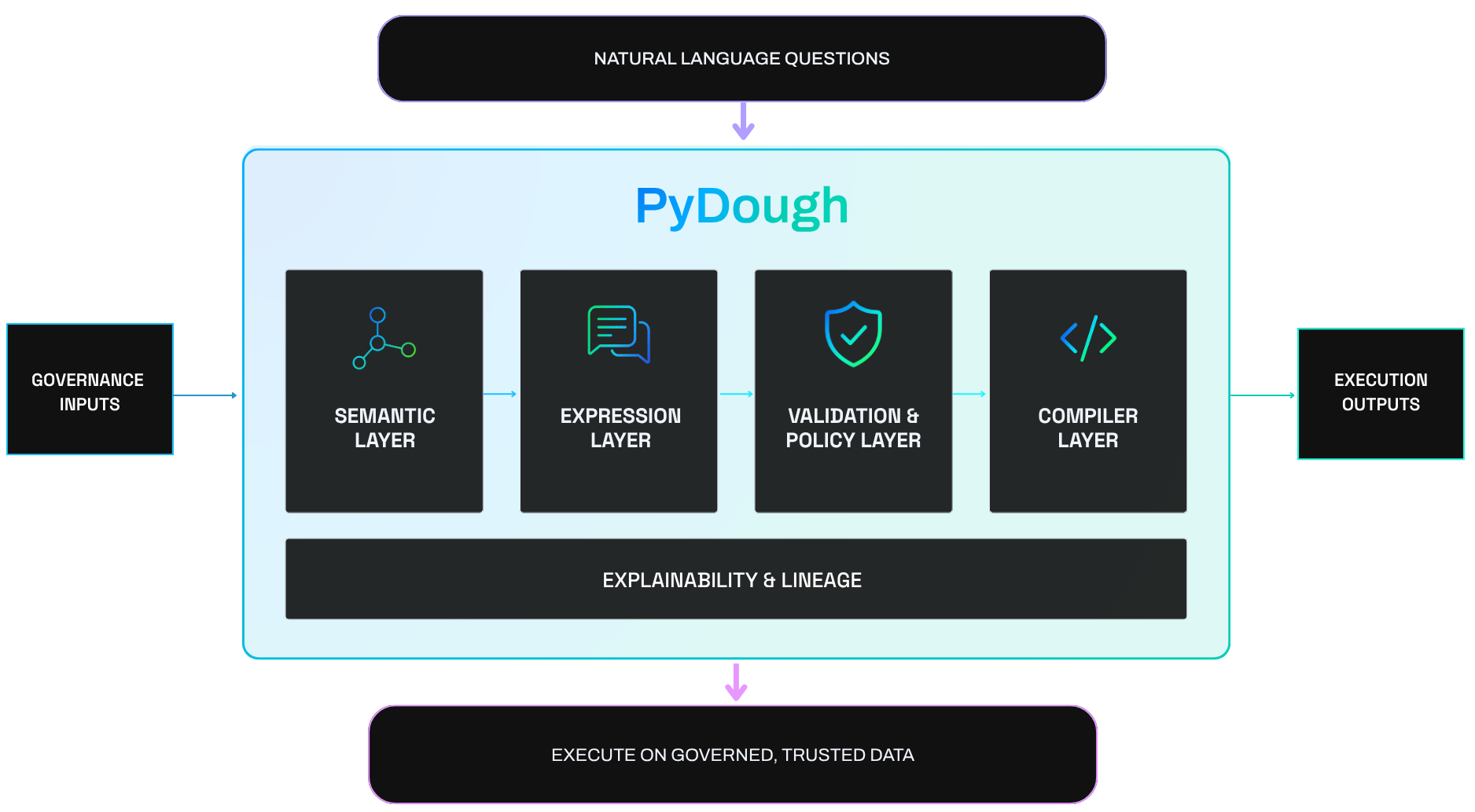
Fully Open Source Trustworthy Text-to-Analytics Stack for Iceberg Data with PyDough and BodoSQL
We demonstrate the first fully open source text-to-analytics stack for Apache Iceberg data in a simple workflow. This stack brings together three open source technologies: PyDough, BodoSQL, and Apache Iceberg.
New Interactive BodoSQL for the AI Era
We introduce the latest version of BodoSQL, designed for high-performance interactive query execution on massive datasets. We introduce a new C++-based execution backend that reduces query startup latency while preserving scalability and performance.
Building a Native GPU Reader for Apache Iceberg
Here is a deep look into how we designed our GPU-native Iceberg source operator, the architectural tradeoffs we weighed, and the specific edges we encountered while making the storage layer safe for hardware acceleration.
Have questions or want a personalized demo? Just give our team a shout—we’d love to chat!

