
%20(1200%20x%20485%20px).png)


When you build a distributed execution engine on modern GPUs, I/O performance quickly becomes the critical path. In a previous post, we discussed how Bodo’s SPMD (Single Program, Multiple Data) architecture scales GPU DataFrames by avoiding the scheduling overhead of task-based engines. To truly capitalize on that architecture, the storage layer has to keep up.
When we set out to build our GPU-accelerated Iceberg write operator we knew that writing Parquet files from device memory is relatively simple (cudf::io::write_parquet handles this beautifully). However, writing to Apache Iceberg is not just about dumping Parquet files. Iceberg dictates strict requirements for hidden partitioning, complex sort orders, and rich file-level metrics (min, max, null counts) that are required for query pruning.
Doing all of this efficiently on a distributed GPU cluster without constantly transferring to the host CPU is complex and our solution to this problem is the topic of this blog. Here is a look at the internals of how we built our native GPU Iceberg writer.
To understand the design constraints of our GPU Iceberg sink, specifically why we can't just write files the moment data arrives, you have to look at the execution model driving it. As we detailed in our previous post on scaling GPU DataFrames, Bodo bypasses the standard driver/worker model in favor of an MPI-based SPMD (Single Program, Multiple Data) architecture.
In a traditional task-based engine like Spark or Dask, a central scheduler breaks the query into discrete tasks. Data is typically materialized at task boundaries, and writing to storage is just another mapped task orchestrated by the driver.
Bodo operates entirely differently. It compiles the query into a push-based streaming pipeline. All ranks (processes) in the cluster boot up simultaneously and execute the exact same compiled C++ binary. There is no central scheduler telling nodes what to do. Data simply flows through the physical operators in asynchronous chunks.
To contextualize where this writer fits, it helps to look at the three archetypes of physical operators in our push-based architecture. Rather than waiting for downstream nodes to request data, upstream operators actively hand off processed batches the moment they are ready. Sources act as the pipeline's ingress, pulling data from storage and generating the initial streams. Batch processors handle the intermediate compute, they take in an incoming batch, apply transformations like filters or hash-joins, and immediately produce a new batch for the next downstream node. Sinks, like our new PhysicalGPUWriteIceberg operator, are the terminal endpoints. They consume incoming batches, orchestrate local state and external I/O, and act as the final drain for the pipeline.
For a sink operator like our Iceberg Writer, this architecture has the following implications:
By eliminating the centralized scheduler, we remove the task orchestration overhead that normally suffocates high-throughput GPU pipelines. The trade-off is that the complexity of state management, stream ordering, and termination moves directly into the physical operators themselves.
At a high level, our PhysicalGPUWriteIceberg operator is a stateful sink. In a streaming engine, we receive data in small, continuous batches. If we wrote a Parquet file for every incoming batch, we’d create the dreaded small files problem, destroying Iceberg scan performance down the line.
Instead, we operate on an accumulate-and-flush cycle:
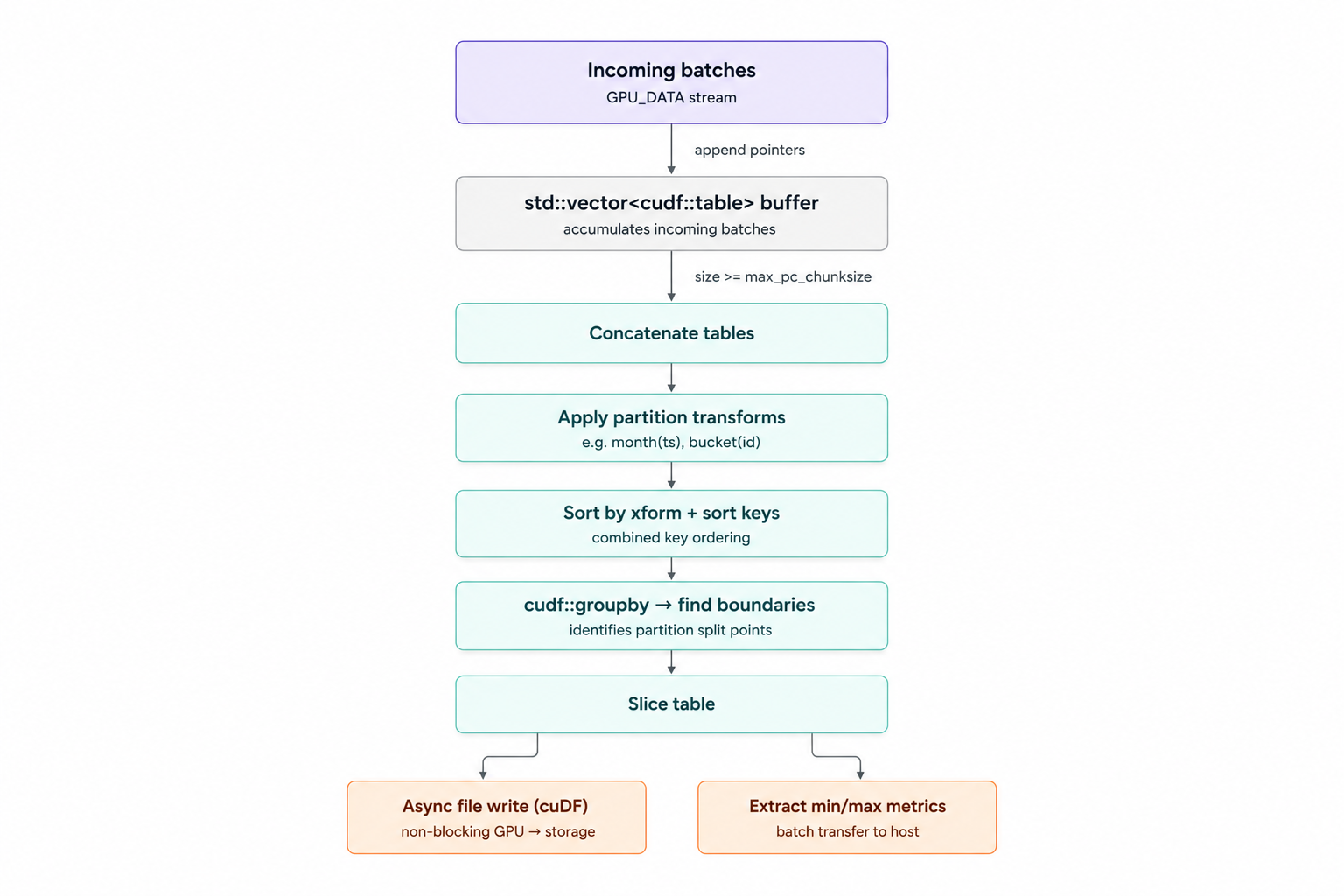
We accumulate std::shared_ptr<cudf::table> references without eagerly concatenating them. Once our accumulated buffer size exceeds a threshold (or the pipeline signals a FINISHED state), we trigger the flush sequence:
But building this operator revealed several interesting engineering challenges.
Iceberg's hidden partitioning is great for end users but can be tricky for execution engines. For example, if a table is partitioned by month(timestamp_col), the final Parquet file should not contain a month column. The partitioning is purely logical and stored in the directory structure (e.g., month=2024-01/) and the metadata catalog.
We have to group our GPU DataFrame by a value that doesn't actually exist in the raw data. Doing this row-by-row on the CPU is trivial, but moving millions of timestamps across the PCIe bus to run Python's datetime logic would ruin our throughput.
To solve this, we implemented Iceberg's transform spec natively on the device using libcudf operations.
During the flush phase, we dynamically generate prepended columns for every partition and sort transform. For example, to handle the month transform, we don't just extract the month; Iceberg expects the integer number of months since the Unix epoch. We implemented this using cudf::datetime combined with vector math:
// Pseudocode of the GPU month transform kernel
auto year_col = cudf::datetime::extract_datetime_component(col, YEAR, stream);
auto month_col = cudf::datetime::extract_datetime_component(col, MONTH, stream);
// months_since_epoch = (year - 1970) * 12 + (month - 1)
auto yr_minus = cudf::binary_operation(year_col, 1970, SUB);
auto yr_mul = cudf::binary_operation(yr_minus, 12, MUL);
auto mo_minus = cudf::binary_operation(month_col, 1, SUB);
auto result_int32 = cudf::binary_operation(yr_mul, mo_minus, ADD);We append these temporary columns to the front of our working_table. We then use cudf::sort_by_key to sort the entire table, and cudf::groupby on these prepended columns to identify the row indices where the partition values change.
Once we have our partition boundaries (e.g., rows 0–1500 are month=2024-01, rows 1500–3000 are month=2024-02), we use cudf::slice to create zero-copy table views. Finally, we drop the prepended transform columns from the view before passing it to cudf::io::write_parquet. The GPU does all the heavy lifting, and the CPU only ever sees the resulting scalar strings used to build the directory paths.
Iceberg uses robust file-level statistics to enable query pruning: exact row counts, null counts, and lower/upper bounds.
Finding the min and max of a column on a GPU is fast via cudf::minmax. However, cudf::minmax returns a scalar on the device. If your DataFrame has 100 columns, you now have 100 min scalars and 100 max scalars sitting in device memory.
The naive solution would be to iterate through these scalars, convert them to Arrow, and serialize them into Iceberg's binary format. But doing this individually results in 200 separate GPU-to-host memory transfers per partition file. The latency overhead of setting up and tearing down the PCIe transfer could overshadow the actual compute time.
Instead of moving scalars individually, we dynamically construct a single, 1-row cudf::table containing all the minimum values, and another 1-row table containing all the maximum values.
std::vector<std::unique_ptr<cudf::column>> min_cols;
for (size_t i = 0; i < output_col_names.size(); i++) {
if (partition_column[i]) {
// Convert the standalone device scalar back into a 1-element device column
min_cols.push_back(cudf::make_column_from_scalar(*min_scalars[i], 1));
}
}
// Build a single table out of all min columns
auto min_table = std::make_unique<cudf::table>(std::move(min_cols));By converting the 1-row table to an Arrow table, we incur exactly one bulk memory transfer. Once the data is on the host, we iterate through the Arrow fields, serialize the values to little-endian bytes according to the Iceberg single-value serialization spec, and populate statistics for manifest files.
Writing a distributed GPU query engine means you can't rely on existing JVM-based or Python-based Iceberg libraries for the data plane. You have to build the logic directly into device memory. By implementing transform evaluation and batched metadata extraction natively in C++/CUDA, we keep the GPUs utilized efficiently.
More importantly, this work reflects a broader principle behind Bodo’s execution engine: performance is not just about accelerating one operation in isolation. The surrounding execution path has to be designed so the GPU can stay in control of the data plane from beginning to end. If partition transforms, file slicing, metadata statistics, or commit preparation constantly force data back through the CPU, the performance gains of device-side compute quickly disappear.
By building Iceberg write support directly into Bodo’s native execution engine, we keep the data on the GPU and make the sink operator a first-class part of the distributed pipeline. The result is not simply a faster Parquet write path, but a GPU-native Iceberg sink that preserves the throughput of the broader distributed pipeline.
To get started using Bodo yourself:
And join the Community Slack to stay in the loop on product releases, new features, and other updates.





