Achieve 10×–100× faster execution — from millions to billions of rows — without OOM errors. Whether in your laptop notebook or production pipelines, just swap the import and go.
Swap with import bodo.pandas as pd.
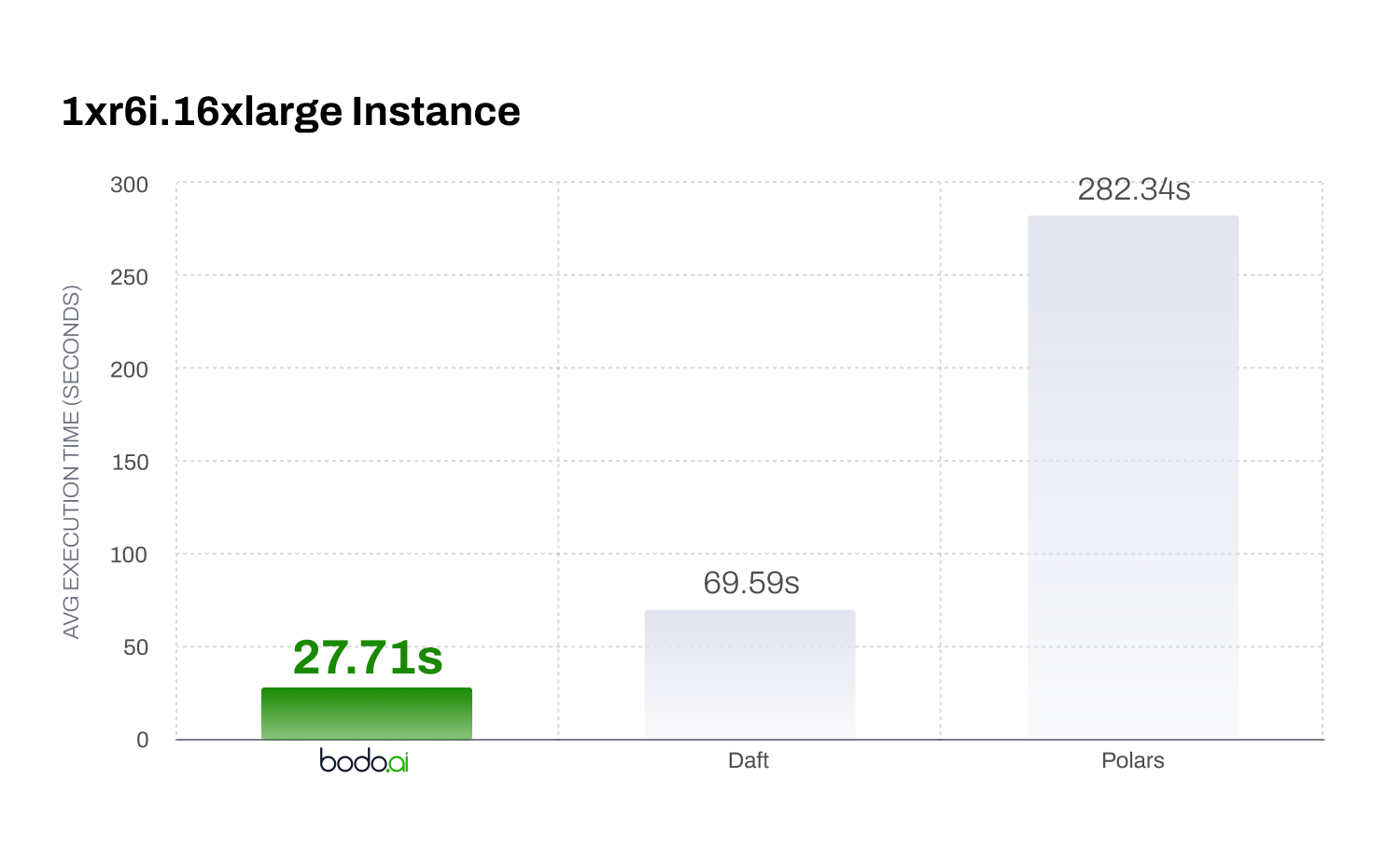
10×–100× faster on production workloads.
Built‑in read_iceberg and to_iceberg with projection, filter, and limit pushdown.
Parallelizes UDFs, ML inference, and ETL — use the same pandas format
to pandas for anything not yet accelerated.
Open source license (Apache 2.0)
Pandas-compatible batch inference, S3 Vectors, and more.
Vectorized execution handles billion-row workloads without OOMs.
Data science, data engineering, feature engineering and others.
FIlter pushdowns, column pruning, partition pruning, streaming parallel writers.
Distribute feature prep and scoring for billions of rows.
Multi-year simulations in pure Python at HPC speeds.
Parallel embeddings, S3 Vectors compatible.




