
%20(1200%20x%20485%20px).png)


In our last blog on the NYC Taxi benchmark, we showed that Bodo DataFrames was much faster than other dataframe systems—all while requiring almost no changes to existing Pandas code. That benchmark highlighted a common tension in the Python analytics ecosystem: systems that preserve the Pandas programming model often struggle to scale efficiently, while systems that scale well typically require adopting new APIs and execution semantics.
In this post, we evaluate that trade-off using the TPC-H benchmark, a widely used standard for large-scale analytical and decision-support workloads. TPC‑H stresses systems with complex joins, aggregations, and filtering across gigabytes of synthetic relational data. These characteristics make it a useful benchmark for understanding how different dataframe systems handle optimization, memory, and distributed execution.
To focus specifically on distributed behavior, we ran the full TPC‑H query suite at scale factor 1000 (~1000 GB). At this scale, single-node dataframe systems typically exhaust memory. Conversely, during distributed execution, performance is dominated by join costs which are highly dependent on join order, communication between nodes, and intermediate materialization costs. We compare Bodo DataFrames, Dask, and PySpark on a cluster of four Amazon EC2 instances (128 physical cores). All benchmark code, configurations, and TPC-H query implementations are available in our GitHub repository.
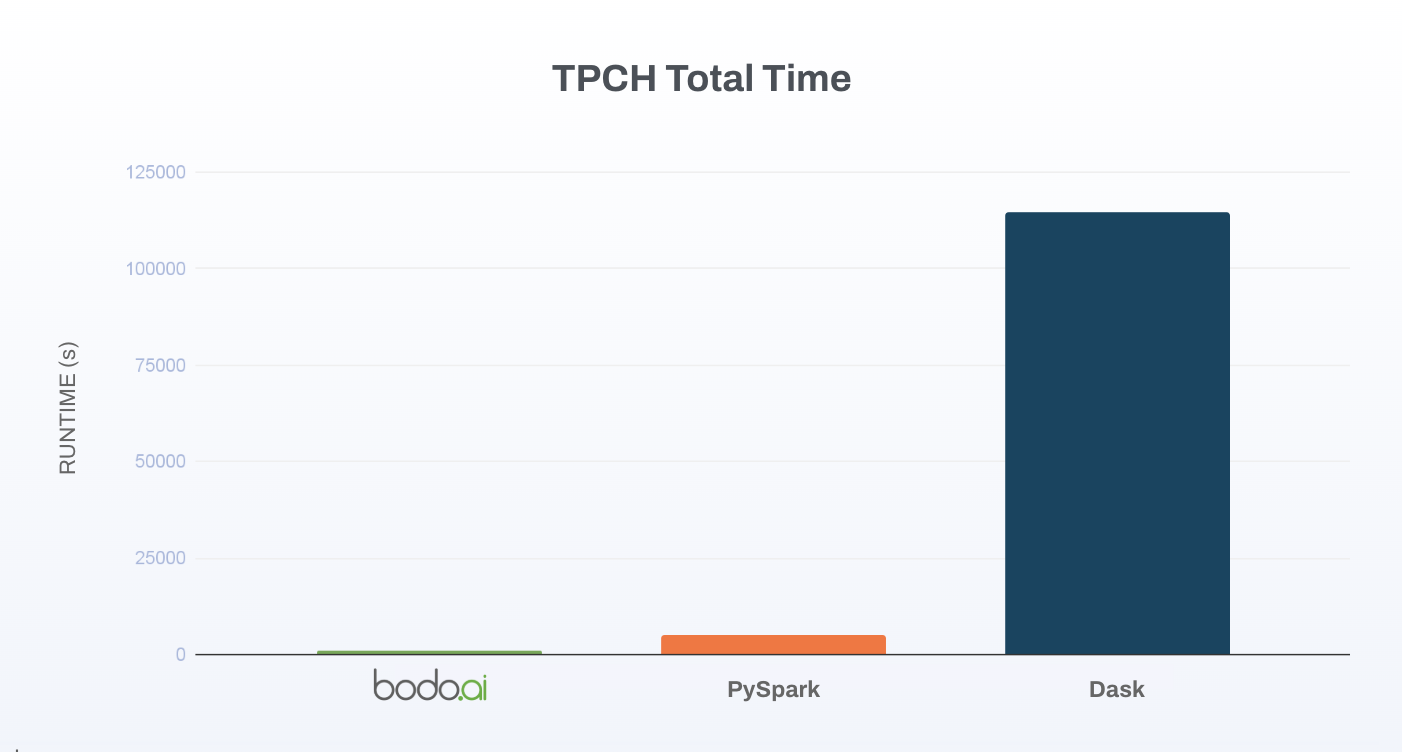
At scale factor 1000:
For Pandas developers looking to scale their applications without the cost and risk of a full refactor, Bodo DataFrames offers a compelling alternative, delivering HPC-level speed with the lowest migration effort by employing a database-grade query planner in combination with a streaming, C++, and MPI backend.
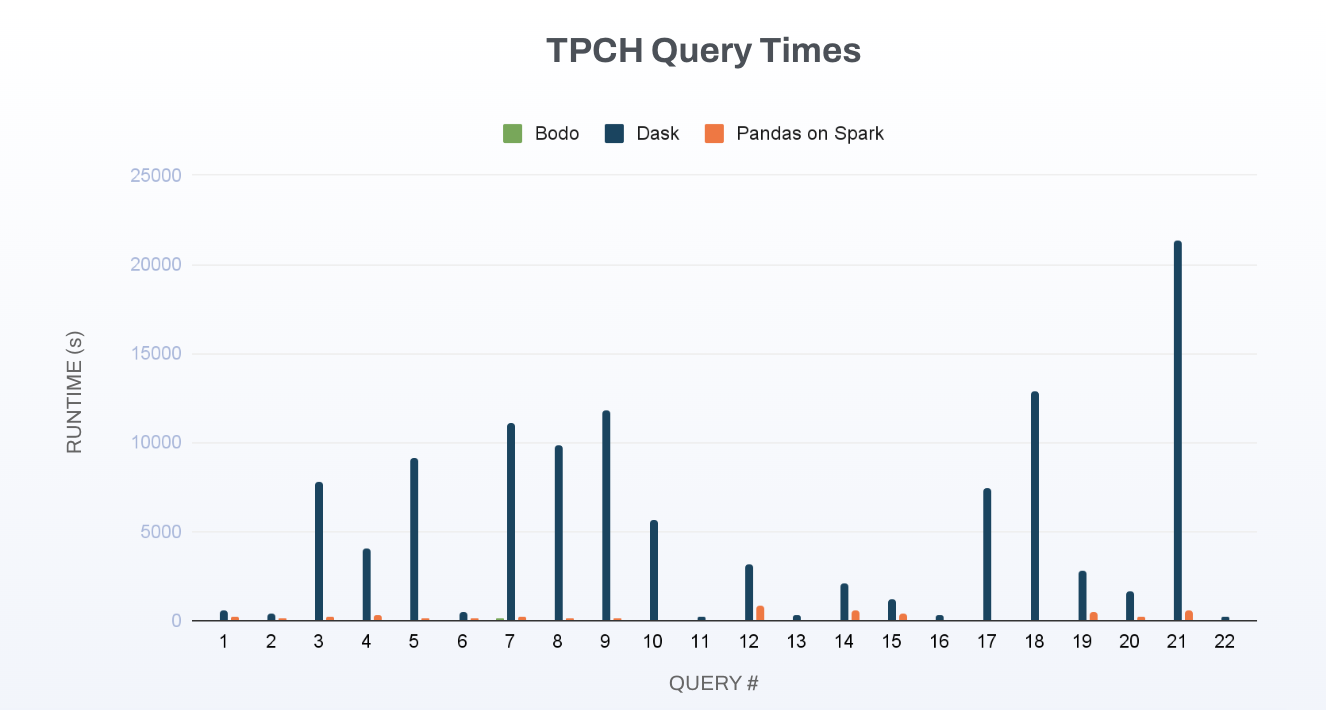
Here we breakdown the times per individual query.
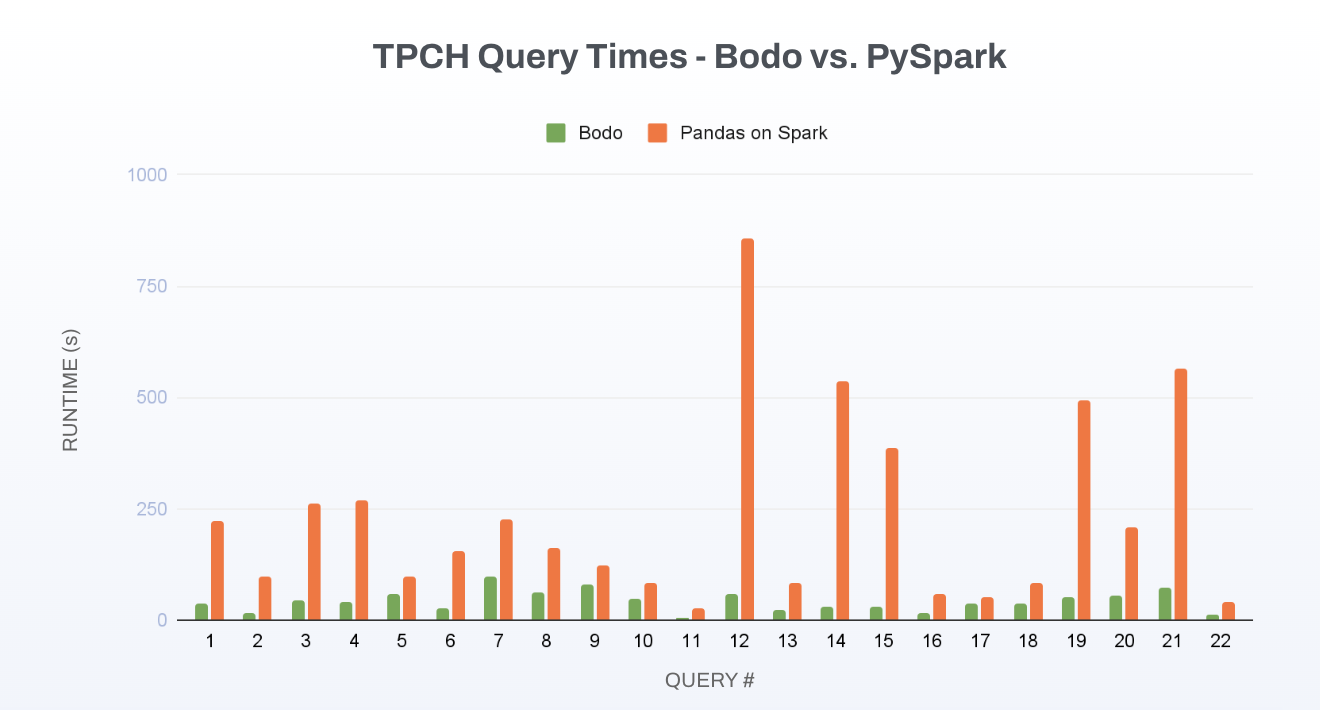
The scale of the Dask results sometimes makes it hard to see the difference between Bodo and PySpark so we duplicate the above graph below absent the Dask data.
Each system was run using its typical distributed deployment on AWS:
TPC‑H consists of 22 immutable SQL queries over a normalized relational schema modeling customers, orders, suppliers, and line items. The queries are designed to stress:
Because these queries combine relational complexity with large data volumes, performance is highly sensitive to query planning, join strategy selection, memory management, and data movement.
Strictly speaking, any implementation that departs from the original, unchanged SQL queries cannot be considered true TPC-H. However, we refer to each of the translations of the SQL originals into the equivalent APIs of the various dataframe systems as if they were TPC-H. The source code and measurement scripts are available at in our Github repo. All of the Dask TPC-H codes were obtained from an official release from the Dask team. For PySpark, we used the Bodo queries with the Pandas on Spark API but had to modify 7 of the queries to work around gaps in that API. For example, Pandas on Spark does not support the Series.isin() operator so we replaced isin() with an equivalent join. We also had to replace unsupported join types in Pandas on Spark with supported joins plus additional operations (e.g., filter).
Each query was executed independently, with no shared state or cached data between runs. We measured end-to-end runtime for all 22 queries, including the I/O of reading Parquet files from S3. This approach captures not only computation but also data movement costs, which are often excluded from benchmarks but frequently dominate real-world analytical workloads at scale.
Although all three systems expose DataFrame-style APIs, their execution models differ fundamentally. The observed performance differences in TPC-H can largely be explained by how each system represents computations, optimizes query plans, and executes distributed workloads.
Bodo DataFrames delivers HPC-level speed and out-of-core, multi-node scale with a one-line import and no refactoring. Key architectural characteristics:
Because execution is compiled and streaming, joins and aggregations execute quickly, and large intermediate results are avoided whenever possible. This execution model maps well to TPC-H, where joins and aggregations dominate runtime.
PySpark serves as a widely-adopted cluster workhorse, leveraging the Apache Spark distributed processing engine, which runs on the Java Virtual Machine (JVM). Its strength lies in its maturity and ability to scale massive workloads. However, its Pandas on Spark API is distinct from the standard Pandas ecosystem, necessitating a steeper porting cost for developers. Migration from Pandas to PySpark requires substantial code rewrites to adopt Spark's execution semantics and API, a process demonstrated on 7 out of 22 TPC-H queries and often demanding specialized knowledge.
Once ported, PySpark automatically manages the distribution of data and computations across the cluster. Performance differences in benchmarks like TPC-H largely stem from its execution model and inherent overheads. Spark's core execution model is based on Resilient Distributed Datasets (RDDs) and an optimized DataFrame/SQL engine (Catalyst Optimizer). While this provides sophisticated query planning, the system often incurs overhead due to:
In summary, PySpark offers power and scale through a mature, distributed SQL engine, but it comes with a higher developer migration cost and performance overheads related to cross-language serialization and memory-intensive intermediate data handling, which was evident in the TPC-H results.
Dask DataFrame’s primary strength is largely preserving the Pandas API while distributing computations across partitions. This makes it easy for Python developers to scale familiar workflows. However, Dask is not a relational query engine and lacks the global, cost‑based optimization that systems like Bodo and PySpark rely on for multi‑table joins and large aggregations. TPC‑H stresses exactly those areas, and Dask’s architecture is not designed for them.
On our hardware configuration—four large EC2 nodes with many cores and large memory—Dask’s default deployment model becomes a bottleneck. A single Python worker per node with many threads increases scheduler overhead and exposes Python‑level limitations, including the GIL in parts of the execution path. These effects compound during TPC‑H’s shuffle‑heavy join patterns.
While Dask can perform well on clusters with many smaller workers or with careful tuning, our goal was an apples‑to‑apples comparison across identical hardware. Under these conditions, the results highlight the gap between a general‑purpose parallel Pandas system and engines explicitly designed for distributed SQL analytics.
Thus, Bodo DataFrames is best for teams with large Pandas applications because it delivers HPC-level performance and out-of-core, multi-node scale with no refactor, while alternatives either demand rewrites (PySpark) or leave performance on the table via shallow optimizers and Python-bound UDFs (Dask).
The TPC-H benchmark is a demanding test of distributed analytical capabilities, and the results clearly highlight a critical trade-off: Bodo DataFrames delivers the best combination of high performance and low migration effort among the tested cluster-computing systems. PySpark, while a cluster workhorse, was significantly slower and required extensive code rewrites. Conversely, Dask preserved the low-effort Pandas API but was orders of magnitude slower, with performance decreasing drastically on the cluster.
Bodo DataFrames uniquely solves this dilemma. By providing HPC-level speed, out-of-core, and multi-node scale through a simple one-line import, Bodo allows teams with extensive Pandas legacy to immediately access high-performance analytics without the high cost, risk, and time sink of a complete code refactor. This combination of top-tier distributed performance with the lowest friction is what truly makes Bodo the top choice, production-ready solution for serious analytical workloads in the cloud.
If you want to evaluate Bodo DataFrames on your own workloads, you can start by running existing Pandas code with Bodo by replacing:
import pandas as pdwith:
import bodo.pandas as pdThe TPC-H benchmark code and other examples are available on our GitHub repository, and we’d love to hear what you’re working on or answer questions in our community Slack!





