
%20(1200%20x%20485%20px).png)


In this third part of our series on Python DataFrames, we return to the NYC Taxi benchmark—a litmus test for practical, large‑scale data processing. In Part 1 and Part 2, the Bodo JIT compiler delivered 2x–250x speedups over Daft, Polars, PySpark, Dask, and Modin/Ray, while requiring only minimal changes to existing Pandas code. These earlier results also underscored a recurring tax with many alternatives: new APIs to learn, refactors that introduce brittleness, and runtime overheads that compound at scale. (See those posts for methodology, code, and environment details.)
This installment adds a new comparison with Bodo DataFrames, which is a high performance and scalable drop-in replacement for Pandas. It preserves the familiar Pandas API—often via a one-line import change—while using a high-performance computing (HPC)-based streaming execution C++ backend aimed at accelerating Pandas code from laptops to clusters even in memory-constrained environments. It transparently uses Bodo JIT under the hood when necessary but doesn’t require the code changes needed when using the JIT compiler directly.
In this post, we run the full NYC Taxi workload and compare Bodo DataFrames with both the earlier systems and the Bodo JIT compiler.
The results: Bodo DataFrames and Bodo JIT deliver comparable runtimes on NYC Taxi and continue to outperform the other systems by 2×–250×. Bodo DataFrames’ streaming design can pull ahead on larger-than-RAM datasets or in tighter memory budgets. It also preserves Pandas idioms, minimizing developer effort and refactoring.
We executed the NYC Taxi benchmark on two setups: a single AWS node with 32 cores and a four-node AWS cluster with a total of 128 cores. In both configurations, Bodo DataFrames delivers top-tier performance while having a programmability advantage with its “change one import” ergonomics and invisible scale‑out.
The larger than memory support column indicates a system’s ability to process data larger than available memory, which means that the system has both streaming and spilling capabilities: streaming lets basic operations flow through the pipeline in batches, while spilling enables whole-dataset operations (e.g., sorting) to use disk as backing storage. For many production Pandas workloads that need to push beyond a single machine’s memory or compute limits, this combination makes Bodo DataFrames the most attractive option, avoiding costly rewrites while scaling cleanly. Note: the runtime axis in the charts below is log-scale.
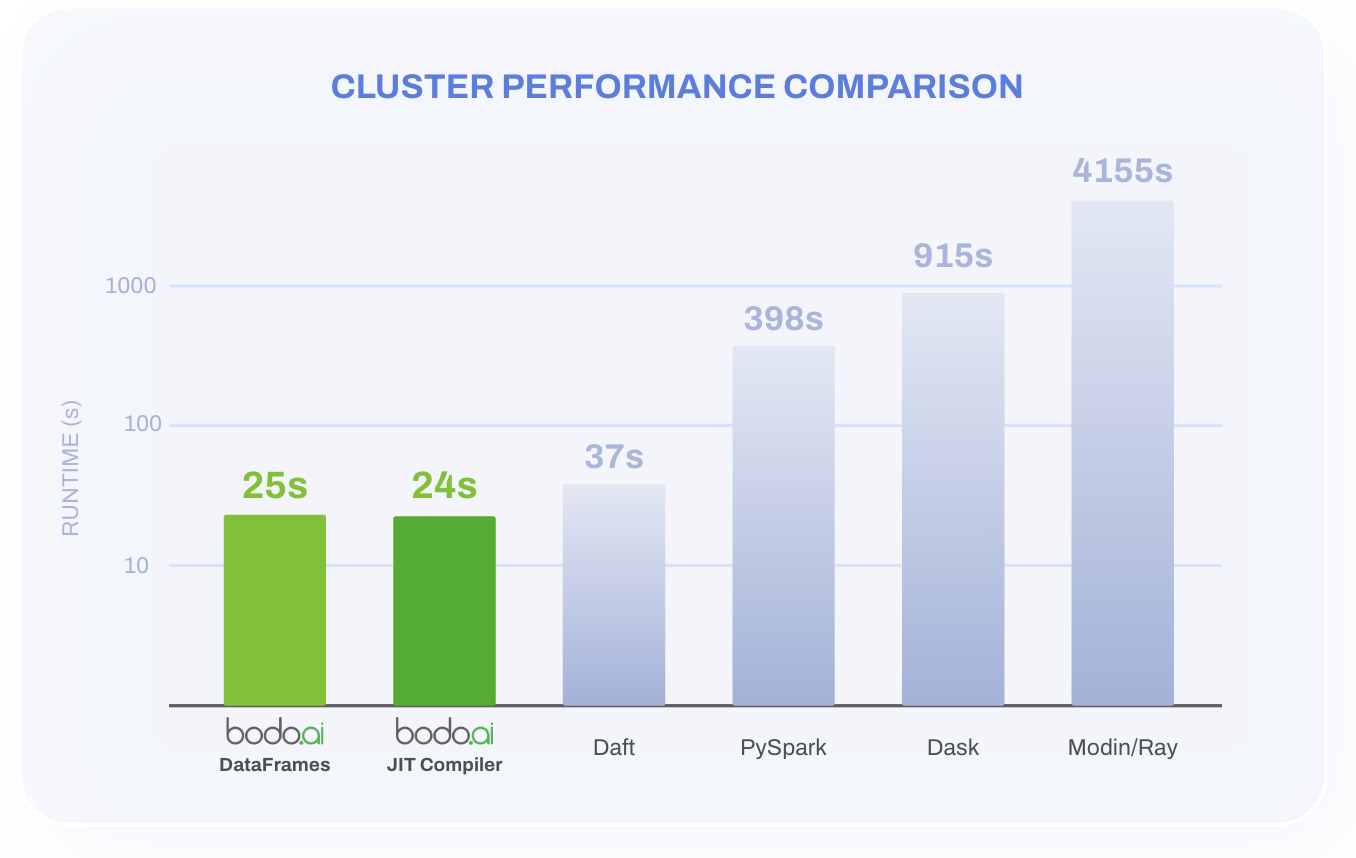
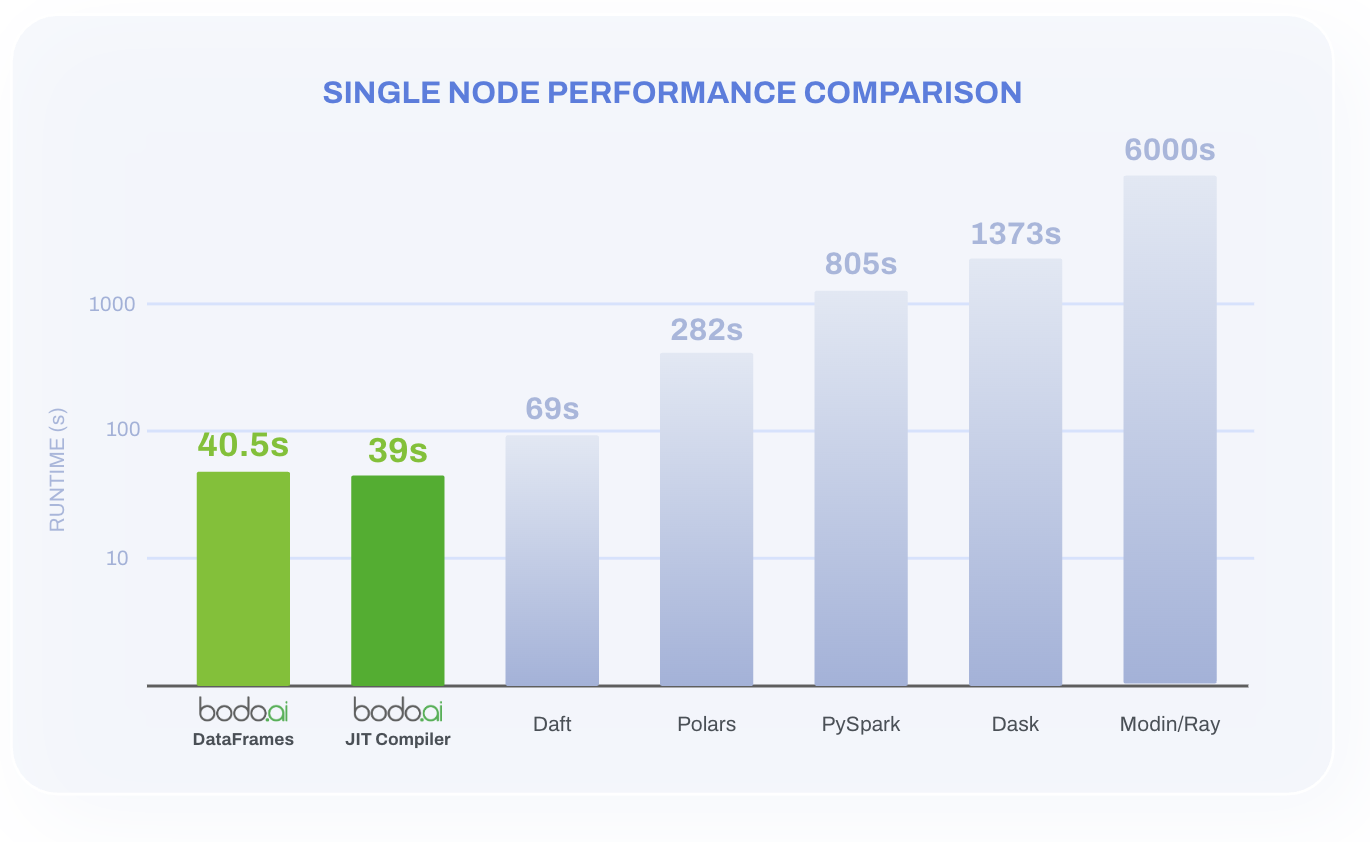
We reuse the setting from the original benchmark which is summarized in the table below:
The NYC Taxi benchmark (our code here, original code here) uses a denormalized HVFHV trips dataset from NYC—about 1.1 billion rows (~24.7 GiB Parquet for trips). It uses core trip fields (timestamps, pickup/drop-off locations, distance, IDs) and runs a simple end-to-end pipeline:
date_with_precipitation flag for precipitation > 0.1This sequence exercises three practical dimensions: (1) I/O throughput for large Parquet/CSV reads, (2) aggregation efficiency over sizable intermediates, and (3) memory resilience when joins/aggregations approach or exceed RAM. It’s a useful proxy for everyday data-engineering pipelines where both total runtime and basic run-to-completion reliability matter.
In this section, we briefly describe the data processing tools with which we compare along two dimensions: how much programmer effort is required versus regular Pandas code and how much performance you can expect as illustrated in the following table. Bodo DataFrames gives warehouse-class speed and out-of-core, multi-node scale with a one-line import via lazy relational optimization; Bodo JIT hits peak speed when you annotate hot paths. Polars and Daft trade Pandas idioms for expression-first APIs and strong lazy engines. PySpark is the cluster workhorse with SQL/DataFrames and the steepest porting cost. Dask and Modin preserve Pandas and parallelize partitions but leave optimizer depth and Python-bound UDFs as ceilings.
In contrast, Bodo DataFrames aims at top-tier, distributed, out‑of‑core performance but with zero refactor.
Our design priorities were: keep the Pandas surface, capture operations lazily, convert to a relational plan, optimize cost-based, execute on a streaming C++ engine across nodes, and compile UDFs when possible with tiered fallbacks for full API coverage.
It’s best for teams with large Pandas estates because it delivers warehouse-class performance and out-of-core, multi-node scale with no refactor, while alternatives either demand rewrites (Polars/Daft/PySpark) or leave performance on the table via shallow optimizers and Python-bound UDFs (Dask/Modin).
You just replace:
import pandas as pdwith:
import bodo.pandas as pdAfter import, the library executes lazily: it collects a sequence of DataFrame/Series operations until data would “escape” (e.g., to Python scalars, output files, etc.). At that point, Bodo lowers those collected operations to a relational form, optimizes with an advanced query optimizer, and runs against the Bodo C++ streaming backend. That combination enables multi‑node parallelism and out‑of‑core execution so that datasets far larger than the cumulative RAM of the machine or cluster can be processed.
User-defined functions (UDFs) are quite common in Pandas and passed to functions such as map, apply, or groupby.agg. Here, Bodo DataFrames leverages Bodo JIT to attempt to compile these UDFs. When successful, these compiled UDFs run at native speeds in the Bodo C++ streaming pipeline without the overhead of transitions back and forth to Python data structures. Non-compilable UDFs will still run but in Python and will incur the aforementioned overheads.
Bodo DataFrames uses an advanced query optimizer that has database-grade capabilities. It transforms naïve logical plans into highly efficient execution strategies through a rich set of rule‑based and cost‑based optimizations, including predicate pushdown, join reordering, column pruning, and set‑operation rewrites. By leveraging detailed column‑ and table‑level statistics, it can make join and filter decisions with precision, often matching or exceeding the performance of hand‑tuned SQL in other engines.
The Pandas API is extensive and Bodo DataFrames natively supports most of its commonly used functionality. When a feature is not directly supported, Bodo DataFrames provides a fallback mechanism to maintain full API compatibility. Depending on the operation, this fallback may invoke the Bodo JIT compiler—keeping the data distributed but interrupting streaming, which can lead to out‑of‑memory errors for very large datasets—or, as a last resort, execute the operation in stock Pandas after converting the distributed DataFrame to a local Pandas DataFrame. This final fallback carries an even higher risk of out‑of‑memory errors; however, in practice, such cases typically operate on data that has already been aggregated or reduced during the streaming phase, making it far more likely to fit in memory on a single node and thus less prone to failure.
1) Total cost of ownership: one‑line import vs. a rewrite
2) Relational optimization without leaving Pandas idioms
3) Out‑of‑core by default, streaming under pressure
4) Transparent scale‑out
5) The speed you need
Benchmarks draw the eye to single numbers, but production success hinges on a composite: wall‑clock time, time‑to‑solution, robustness under memory pressure, and ease of maintaining business logic. The new Bodo DataFrames earns its place by collapsing migration cost to almost zero while still delivering top-tier performance and truly scalable, out‑of‑core execution. You can install Bodo with pip install bodo or conda install bodo, visit our GitHub repository for more information and join the conversation in our community Slack.





