


The Snowflake Data Cloud simplifies data management for data engineers at a near-unlimited scale, while the Bodo Platform brings extreme performance and scalability to large-scale Python data processing. Snowflake and Bodo have combined forces to give data teams the ability to complete very large ETL and data-prep jobs in a fraction of the time, and with better efficiency, than they could with Snowflake alone. This is achieved with Bodo’s supercomputing-style MPI-based parallel approach to data analytics using native Python. Further, as we’ve shown in the past, this approach is also an order-of-magnitude faster – and far more resource-efficient – than using Apache Spark.
Combining these best-in-class storage and compute solutions requires very efficient data movement between the two platforms, which has been a key focus of Bodo’s partnership with the Snowflake team.

Bodo’s Snowflake Ready connector lets Bodo clusters read terabytes of Snowflake data extremely fast. It is built-in and fully automatic ( developers can simply use pd.read_sql()) while delivering high performance similar to Parquet on S3 datasets. In this blog, we walk through an example using this connector and discuss how it works under the hood. We also demonstrate how our integration of the Bodo compiler’s automatic filter pushdown and column pruning optimizations to this connector brings further efficiency to data applications written in Python.
Reading the input data (i.e., data extraction) is usually the first step of a data pipeline and must be fast and scalable. This section demonstrates reading 1TB of data (>8.5 billion rows) from Snowflake using Bodo in under 3.5 minutes. We also compare the performance with reading the same data from Parquet files from AWS S3, showing that the overhead of reading from Snowflake is small.
For this benchmark, we use 1 TB of TPC-H data as input, which is available on all Snowflake accounts in the SNOWFLAKE_SAMPLE_DATA database under the TPCH_SF1000 schema. This schema has 8 tables, and the name and size of each table are listed below. We copied the same data in S3 for comparison.

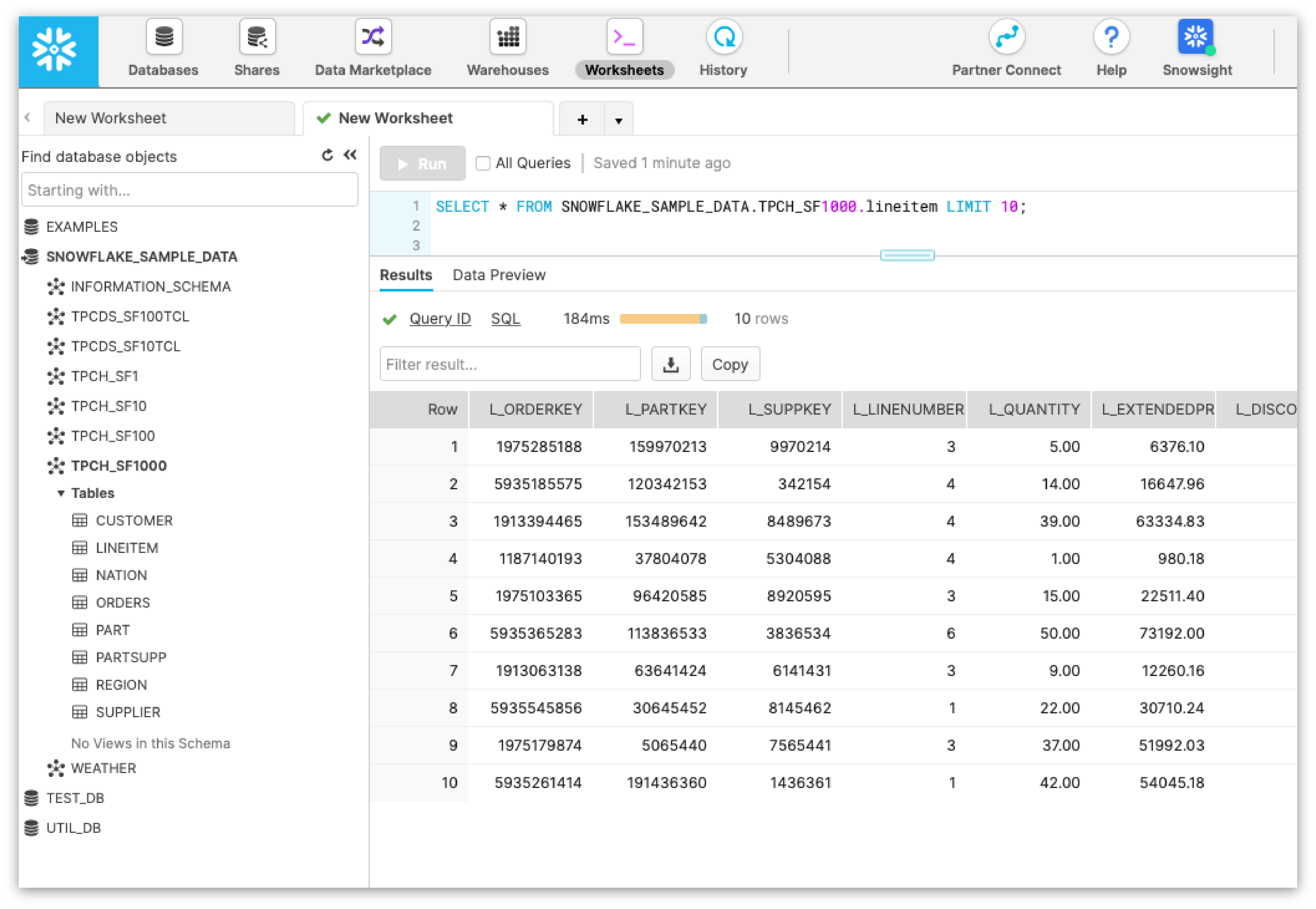
Below is the Python code to read data from Snowflake using Bodo that we ran on the Bodo Platform. We used a cluster of 16 c5n.18xlarge AWS instances with 576 physical CPU cores and 3 TB of total memory. We used a 5X-large Warehouse on the Snowflake side to ensure there is no bandwidth limitation on the warehouse side (although, at this scale, a "large" warehouse is usually enough)
You can monitor the CPU and memory usage by opening a new terminal in Jupyter Lab, ssh into one of the nodes, and using htop:
You can find the CLUSTER_UUID and IP by going to the Clusters menu, and clicking DETAILS under Community Edition Cluster. See the snapshot below.
As the code below shows, Bodo connects and reads data from Snowflake in the same way that Pandas does, which makes it pretty straightforward:
Output:
We monitored one of the nodes in the Bodo cluster while the code was running. As you can see in the figure below, htop shows multiple cores are reading data in parallel from Snowflake. It took only 200 seconds to fetch 1TB worth of data (>8.5 billion rows) from Snowflake with Bodo. To test this without Bodo, you would just need to remove the %%px magic as well as the bodo.jit() decorator. However, we find that regular Python crashes with large data since it cannot scale.

Storing data in Parquet format on S3 is a very common practice for fast big data access, so we compare reading from Snowflake to reading Parquet from S3. Below is the code for reading data from S3, which we ran on the same cluster of 16 c5n.18xlarge AWS instances. You can test this code for free by copying SF1 data in your S3 and using Bodo’s hosted trial.
Output:
Bodo took only ~154 sec to read 1TB of data. Snowflake, as expected, takes a bit longer as it incurs some overhead by executing the query and returning the data in Arrow format.

We have just demonstrated reading entire tables. However, most practical use cases need just a portion of the data in each run. The Bodo JIT compiler is able to select only the necessary columns, and push down filters automatically. This example code demonstrates this optimization using the same TPC-H data:
In this code, the data is filtered using l_linenumber and l_orderkey columns, and only the l_suppkey column is used afterward. Regular Python would execute this code line by line, which would send the whole SELECT * FROM LINEITEM query to Snowflake. However, Bodo optimizes the query to read only the necessary columns and pushdown the filters:
Optimizing the query manually is difficult and error-prone for complex programs, so this feature is very useful for simplifying data pipelines.
How does Python analytics with Snowflake work? For a workflow built using regular Python, the Python/pandas application typically uses pandas.read_sql() call with a query to read Snowflake data (internally stored on object storage like S3), which transfers the results back through a single communication pipe – which is very slow. Pandas reads from Snowflake using a single core and is also quite slow. This also means that users cannot take advantage of the full compute capabilities of the compute infrastructure.
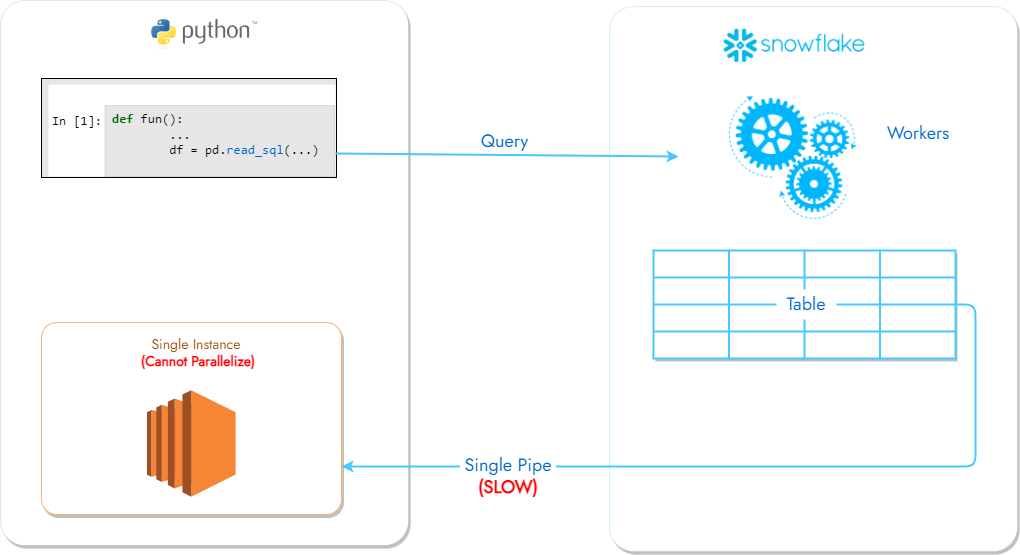
In contrast, using the Bodo JIT compiler, the query in pandas.read_sql is optimized (e.g., remove unused columns, pushdown filters) and sent to Snowflake. The data warehouse computes the results and transforms the output into Apache Arrow format. Bodo’s distributed fetch mechanism reads the data into parallel chunks on which the cores will execute the application in parallel. This can be orders of magnitude faster than using regular JDBC/ODBC connectors.

Bodo automatically handles the load balancing of the data across cores. This distributed fetch implementation of Bodo has close to parquet-read performance.
Finally, Bodo’s JIT compiler automatically parallelizes the application, and each core executes the parallelized application on its own chunk of data loaded by the distributed fetch.
With fast distributed fetch and parallelized computation, Bodo enables developers to build highly performant data pipelines. Python simplicity means that the code developed on your laptop is already production-ready. We are working with the Snowflake engineering team on improving this connector in various ways (e.g., implementing an automatic efficient distributed write mechanism).
Simplifying data engineering at large-scale requires compute and storage technologies that deliver scalability and efficiency automatically. Bodo’s connector for Snowflake allows running Python analytics code on massive data stored in a fully-managed cloud-native data warehouse. The Bodo-on-Snowflake stack allows data engineers to build innovative, high-performance, efficient and cost-effective data applications quickly, while maintaining them with little effort.
We are excited to see the impressive data applications you can build with Bodo and Snowflake. See Bodo in action.





